



My batis

- 支持定制化
SQL,即需要自己写SQL - 封装了
JDBC,不需要手动设置和获取结果集 - 可以通过
XML和注解配置映射,可以将SQL语句写到XML或者注解中
配置
配置文件的顺序
properties?,settings?,typeAliases?,typeHandlers?,objectFactory?,objectWrapperFactory?,reflectorFactory?,plugins?,environments?,databaseIdProvider?,mappers?
新建一个xml,填入以下内容
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
-
environments中可以配置多个数据库连接 -
<transactionManager type="JDBC"/>表示事务的管理类型是JDBC,也就是事务的提交、回滚需要手动完成 -
<dataSource type="POOLED">表示使用数据库连接池 -
数据库的驱动如果是
MySQL可以按照以下格式设置 -
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
environments标签
在所有的environment标签中都有一个id属性,这个属性用来标识当前的这个环境配置的名称
而environments标签中有一个属性default,这个属性值可以指定环境,用来设置默认使用环境的id,id不能重复
environment标签
在这个标签中,可以设置事务的管理方式、数据源、数据库连接时所需的属性
事务管理方式<transactionManger type="值" />,取值有两种类型:
JDBC:表示当前环境中执行SQL时,使用的是JDBC原生的管理方式MANAGED:被管理
dataSource标签
用来配置数据源,也有一个属性type,用来设置数据源的类型,取值有三种类型:
POOLED:- 表示使用数据库连接池缓存连接
- 下次获取数据时,只需要在数据连接池中取出连接
UNPOOLED:- 表示不使用数据库连接池
JNDI:- 表示使用上下文中的数据源
通过properties加载连接信息
新建一个properties配置文件,加上前缀,例如:以下配置信息中的jdbc就是前缀
jdbc.url=连接信息
jdbc.username=用户名
jdbc.password=密码
jdbc.driver=驱动
引入:在核心配置文件中的<configuration></configuration>标签中添加<properties resource="文件名.properties" />
在需要的位置使用${前缀名.属性}
例如:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="jdbc-connection-config.properties" />
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mappers/UserMapper.xml"/>
</mappers>
</configuration>
类型别名
在映射文件的查询的标签中需要指定resultType,而结果类型的值是全类名,每次都要写全类名会变的比较麻烦
在核心配置文件按照一定的顺序添加
<typeAliases>
</typeAliases>
Aliases中文为别名
alias,读音为ˈeɪliəs
在这个标签内,添加<typeAlias type="全类名" alias="别名" />,第二个属性alias也可以不进行设置,如果不设置,则默认是以类名作为别名,并且不区分大小写
例如:
<typeAliases>
<typeAlias type="com.moyok.ajax.bean.User" alias="User" />
</typeAliases>
在之后就可以直接使用User了,也可以使用user,甚至UsEr,这个别名不区分大小写
<select id="getUsers" resultType="User">
select * from user;
</select>
给一个包中的所有类都设置别名
也可以给一个包中的所有类都设置别名,在核心配置文件中使用<package name="包名" />的方式进行设置
例如:
<typeAliases>
<package name="com.moyok.ajax.bean" />
</typeAliases>
mappers标签
用来引入映射文件,在里边可以使用<mapper resource="路径/映射文件.xml" />引入
也可以通过包名引入映射文件:
- 这里的包名就是
resource目录下存放映射文件的一级级的目录 - 以包引入文件时有严格的要求,需要保证
mapper接口所在的包要和映射文件所在的包一致 Mapper接口的名字要和映射文件的名字一致
<mappers>
<package name="com.moyok.ajax.Mapper"/>
</mappers>
例如只有按照以下的格式使用上面的包导入的语句才会生效
└─src
└─main
└─java
│ └─com
│ └─moyok
│ └─ajax
│ │
│ └─Mapper
│ UserMapper.java
└─resources
└─com
└─moyok
└─ajax
└─Mapper
UserMapper.xml
使用
- 创建表
- 创建表所对应的实体类,尽量使用包装类,创建构造方法、
getter、setter - 创建
Mapper接口 - 创建映射文件
创建Mapper接口
Mapper接口可以看作之前的DAO,区别是Mapper仅仅是接口,不需要提供实现类
接口命名规则实体类Mapper
创建映射文件
ORM(Object Relationship Mapping),对象关系映射
-
对象代表
Java实体类的对象 -
关系代表关系型数据库
-
映射代表两者之间的对应关系,映射如下:
-
Java 数据库 类 表 属性 字段 对象 记录
-
映射文件xml的命名规则:实体类Mapper.xml,和接口名字保持一致
- 一个映射文件对应一个实体类和一张表
- 映射文件用来编写
SQL语句 - 映射文件存放位置:
src/main/resource/mappers目录下
XML文件内容:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="Mapper接口的全类名">
</mapper>
在<mapper></mapper>标签中可以写需要进行的操作标签:
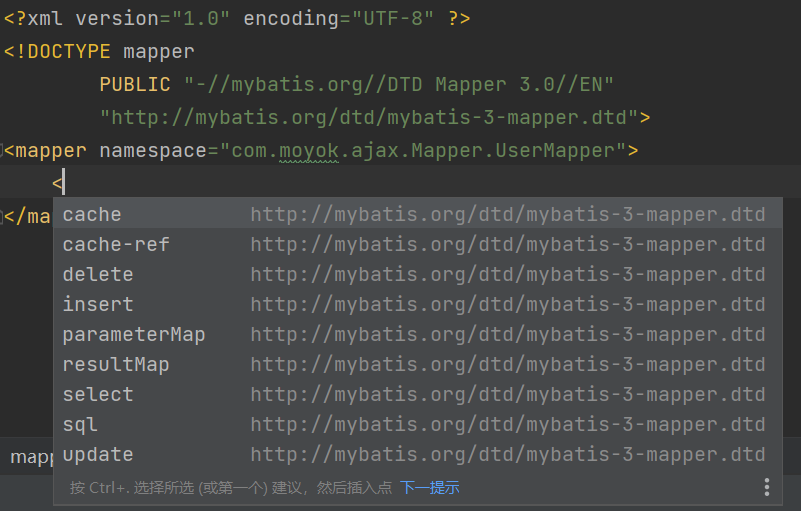
需要将:
UserMapper接口名和MyBatis的映射文件<mapper namespace="接口全类名">保持一致- 将方法名和
<mapper></mapper>标签中的操作标签的id进行对应 - 最后需要在核心配置文件中引入这个
Mapper- 在
<mappers></mappers>标签中- 添加
<mapper resource="文件夹/映射文件.xml" />
- 添加
- 在
例如:
UserMapper.java
package com.moyok.ajax.Mapper;
import com.moyok.ajax.bean.User;
public interface UserMapper {
/**
* 通过id查询用户
* @param id
* @return
*/
User queryUserById(Integer id);
}
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.moyok.ajax.Mapper.UserMapper">
<select id="queryUserById" >
select * from user where id = #{id}
</select>
</mapper>
配置文件.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/book"/>
<property name="username" value="root"/>
<property name="password" value="20020327"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mappers/UserMapper.xml"/>
</mappers>
</configuration>
在Java代码中使用
步骤:
- 加载核心配置文件,使用
org.apache.ibatis.io包下的Resources类的静态方法getResourceAsStream以流的形式进行加载,返回一个输入流 - 实例化一个
SqlSessionFactoryBuilder对象 - 通过
SqlSessionFactoryBuilder的bulid(输入流)的方式加载一个SqlSessionFactory实例 - 通过
SqlSessionFactory实例的openSession()方法获取一个SqlSession实例 - 通过
SqlSession实例的getMapper(自行创建的Mapper接口的.class)获取一个相应的Mapper实例 - 最后再调用相应的实例的方法可以看到执行结果
@Test
void contextLoads() throws IOException {
// 以流的方式加载配置文件
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
// 获取SqlSessionFactoryBuilder
SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
// 使用builder构建SqlSessionFactory对象,将配置文件的流传进去
SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(resourceAsStream);
// 获取一个SqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取自定义的Mapper接口的实例
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
System.out.println("userMapper.queryUserById(1) = " + userMapper.queryUserById(1));
// 可以使用以下方法提交事务
sqlSession.commit();
// 关闭会话
sqlSession.close();
}
底层采用的设计模式的是代理模式
如果在获取sqlSession时,调用sqlSessionFactory的openSession方法时,如果传入一个参数true,就代表自动提交事务SqlSession sqlSession = sqlSessionFactory.openSession(true);
简单的查询
首先需要确定好需要写的查询语句返回的记录的条数和类型
-
需要设置接口中相应的方法返回的数据类型
-
在
Mapper.xml配置文件中的<select></select>标签的属性上,指定resultType="类型"结果的类型或者resultMap-
resultType是默认的映射关系,当字段无法和成员变量相匹配时,此时相应的变量值为null或者默认值 -
resultMap时自定义的映射关系,当字段名和成员变量中的名字不相同时,需要进行自定义 -
<select id="queryUserById" resultType="com.moyok.ajax.bean.User"> select * from user where id = #{id} </select> <select id="getUsersCount" resultType="java.lang.Integer"> select count(*) from user </select>
-
-
如果只有一条,可以让接口中的方法返回一个对象
-
如果有多条记录,可以让其返回一个
List<T>-
此时将接口中的相应方法的返回值设置为
List<T> -
在映射文件中的
<select></select>标签上的resultType值为T,不能够写为List<T>或者List -
例如
<select id="getUsers" resultType="com.moyok.ajax.bean.User"> select * from user; </select>/** * 查询所有用户信息 * @return */ List<User> getUsers();
-
IDEA设置核心配置文件模板
文件->设置->编辑器->文件和代码模板->点击加号

这个时候右键->新建就有了MyBatis Config
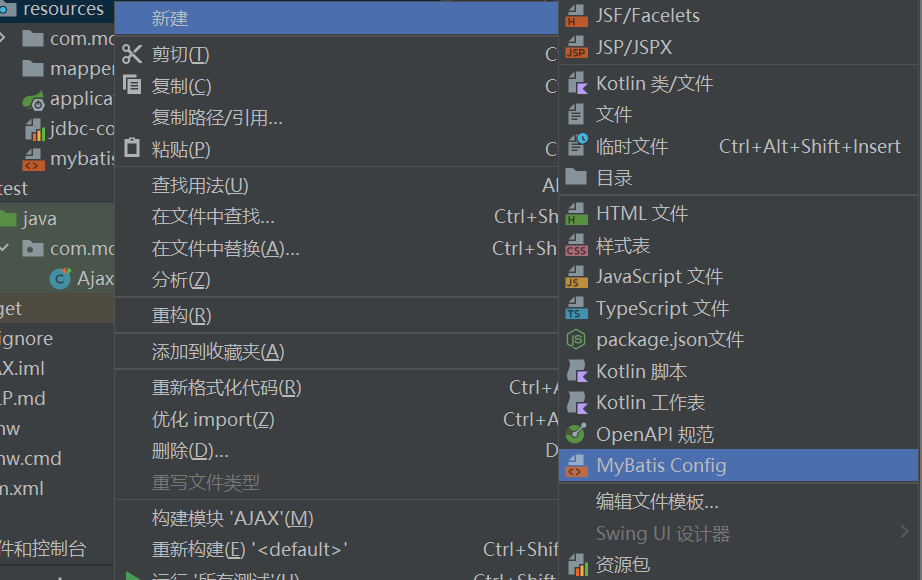
同样的Mapper也可以添加到文件模板
因为每次代码的步骤都差不多,所以可以试着封装SqlSessionUtil 工具类
MyBatis 获取接口中的方法的参数
有两种方式:
${}本质是字符串拼接,可能会出现SQL注入#{}本质是占位符赋值,尽量用这种方式
/**
* 根据id获取用户
* @param id
* @return
*/
User getUserById(Integer id);
<select id="getUserById" resultType="User">
select * from user where id = #{id};
</select>
获取参数的情况分为多种:
情况1:Mapper接口方法的参数为单个变量时
以下的的情况就属于单个变量
/**
* 根据id获取用户
* @param id
* @return
*/
User getUserById(Integer id);
<select id="getUserById" resultType="User">
select * from user where id = #{id};
</select>
这个时候{名字}中的名字可以是任意的,因为只有一个参数
例如也可以写为
<select id="getUserById" resultType="User">
select * from user where id = #{asdfasd};
</select>
情况2:Mapper接口的方法参数为多个变量
例如
int getUserByUsernameAndPassword(String username, String password);
方式1:使用变量名进行匹配
<select id="getUserByUsernameAndPassword" resultType="java.lang.Integer">
select count(*) from user where username = #{username} and password = #{password};
</select>
方式2:使用参数顺序进行匹配,从param1开始
<select id="getUserByUsernameAndPassword" resultType="java.lang.Integer">
select count(*) from user where username = #{param1} and password = #{param2};
</select>
也可以变量名和param数字配合起来用
MyBatis会将这些参数放入到Map中,以变量名/param数字为键,以具体的值为值
情况2 可以手动将参数放入Map中
如果是手动放到Map中,那么此时的查询方式不受印象,#{名字}中的名字只需要和Map中的一个key相同就可以
<select id="loginUserByMap" resultType="com.moyok.ajax.bean.User">
select * from user where username = #{username} and password = #{password};
</select>
Map<String, Object> map = new HashMap<>();
map.put("username", "admin");
map.put("password", "admin");
System.out.println("mapper.loginUserByMap(map) = " + mapper.loginUserByMap(map));
User loginUserByMap(Map<String, Object> info);
情况3 Mapper接口中的参数是一个实体类对象
如果是实体类对象时,#{名字}中的名字就可以为相应的属性名
User user = new User();
user.setEmail("songxiaoxu2002@qq.com");
System.out.println("mapper.loginUserByUser(user) = " + mapper.loginUserByUser(user));
<select id="loginUserByUser" resultType="com.moyok.ajax.bean.User">
select * from user where email = #{email};
</select>
User loginUserByUser(User user);
情况4 命名参数
使用@Param("名称")
int getUserByUsernameAndPassword(@Param("uuu") String username, String password);
这个在使用时,可以按照#{名称}的格式使用
<select id="getUserByUsernameAndPassword" resultType="java.lang.Integer">
select count(*) from user where username = #{uuu} and password = #{password};
</select>
查
如果查询出的数据有多条,不能直接通过一个实体类对象进行接收,否则会抛异常
如果查询的返回结果是单条记录,并且返回的字段的个数只有一个,并且这个字段的类型是基本数据类型,可以在resultType=""设置基本数据类型,例如int可以设置为:
java.lang.IntegerIntegerintegerintInt
等
这是MyBatis早就给提供好默认的类型别名
根据官方文档,可以看出,所提供的别名如下:
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
使得查询结果返回一个Map
当查询结果只有一条数据时,那么此时会将这条数据的字段名映射为key,这个字段的值会被映射为value
Map<String, Object> getUserByIdToMap(Integer id);
<select id="getUserByIdToMap" resultType="java.util.Map">
select * from user where id = #{id};
</select>
mapper.getUserByIdToMap(12).forEach((k, v) -> {
System.out.println("key = " + k + ", value = " + v);
});
应用场景:
- 查出来的数据只有
1条 - 查出来的数据没有对应的实体类与之对应,例如多表查询出来的单条记录
- 当
Map作为对象返回到前端时,这个时候返回的是一条json
多条记录返回Map
也可以使得多条记录也返回一个Map
可以将返回的结果写为List<Map<String, Object>>
当返回结果为List时,<select>标签中的resultType只能为<>中的内容,例如List<Map<String, Object>>的resultType为Map
在之前的代码中,会发现有一个错误提示:

可以给一个Map返回值的方法使用@MapKey("键名")注解,这个时候会让所有的记录都直接的放到一个Map中,并以键名作为注解
例如:以id(整型)为键,查询所有的用户
<select id="getAllUserToMap2" resultType="java.util.Map">
select * from user;
</select>
@MapKey("id")
Map<Integer, Object> getAllUserToMap2();
mapper.getAllUserToMap2().forEach((k, v) -> {
System.out.println("key = " + k + ", value = " + v);
});
结果为:
key = 1, value = {password=admin, id=1, email=\admin@moyok.xyz, username=admin}
key = 9, value = {password=guest, id=9, email=guest@moyok.xyz, username=guest}
key = 10, value = {password=123456a, id=10, email=songxiaoxu2002@qq.com, username=adminNB}
key = 11, value = {password=admin66, id=11, email=admin@cloudreve.org, username=admin66}
key = 12, value = {password=123456a, id=12, email=songxiaoxu2002@qqq.com, username=songxiaoxu}
key = 13, value = {password=MyBatis, id=13, email=songxiaoxu, username=MyBatis}
而这个时候如果转化成JSON,返回到前端的数据为:
{
"1": {
"password": "admin",
"id": 1,
"email": "\\admin@moyok.xyz",
"username": "admin"
},
"9": {
"password": "guest",
"id": 9,
"email": "guest@moyok.xyz",
"username": "guest"
},
"10": {
"password": "123456a",
"id": 10,
"email": "songxiaoxu2002@qq.com",
"username": "adminNB"
},
"11": {
"password": "admin66",
"id": 11,
"email": "admin@cloudreve.org",
"username": "admin66"
},
"12": {
"password": "123456a",
"id": 12,
"email": "songxiaoxu2002@qqq.com",
"username": "songxiaoxu"
},
"13": {
"password": "MyBatis",
"id": 13,
"email": "songxiaoxu",
"username": "MyBatis"
}
}
处理模糊查询
由于模糊查询比较特殊,所以只能使用${名称}填充值
List<User> getUsersLike(String like);
<select id="getUsersLike" resultType="com.moyok.ajax.bean.User">
select * from user where username like '%${like}%';
</select>
mapper.getUsersLike("ba").forEach(System.out::println);
如果使用的是#{},则查询语句就相当于,因为```${}``的本质相当于字符串拼接,所以只能使用这个
select * from user where username like '%?%';
方式2:使用MySQL中的字符串拼接concat()函数,这个时候就可以使用#{}了
<select id="getUsersLike" resultType="com.moyok.ajax.bean.User">
select * from user where username like concat('%', #{like}, '%');
</select>
方式3:使用"%"#{名称}#的方式拼接,最常用
<select id="getUsersLike" resultType="com.moyok.ajax.bean.User">
select * from user where username like "%"#{like}"%";
</select>
批量删除
delete from 表名 where 字段 in (值1, ..., 值n);
可以在MyBatis中使用${名称}进行填充
例如
int deleteUserInId(String id);
<delete id="deleteUserInId">
delete from user where id in (${id});
</delete>
mapper.deleteUserInId("1, 9")
返回结果为一个整型数字,用来表示影响的记录的条数,而在这个例子中,删除了两条记录,此时返回的是2
如果进行openSession时没有设置自动提交事务,那么,此时需要在最后手动的提交一下事务才能将数据删除掉sqlSession.commit();
添加数据时获取自增的主键
-
效果为插入数据时,能够获取到插入的这条数据的主键的值
-
需要在
insert标签中设置useGeneratedKeys="true",还需要设置keyProperty="传进来对象的某个属性",一般来说就是给实体类的相应的属性进行赋值 -
User user2 = new User(); user2.setEmail("123@ddd.com"); user2.setPassword("666***66"); user2.setUsername("username123"); System.out.println("mapper.insertUser(user) = " + mapper.insertUser(user2)); System.out.println("id为:" + user2.getId()); -
int insertUser(User user); -
<insert id="insertUser" useGeneratedKeys="true" keyProperty="id"> insert into user(username, password, email) values (#{username}, #{password}, #{email}); </insert>
因为方法的返回值只能是执行SQL语句后所影响的记录的条数,所以无法将自动递增的主键以返回值的形式返回,只能放到当前传入的实体类对象中
自定义映射resultMap
在字段名和实体类中的属性不一致的时候,可以通过resultMap进行自定义映射
例如表的结构如下:
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| username | varchar(25) | NO | UNI | NULL | |
| password | varchar(20) | NO | | NULL | |
| email | varchar(50) | YES | UNI | NULL | |
+----------+-------------+------+-----+---------+----------------+
实体类如下:
public class User2 {
Integer id1;
String username1, password1, email1;
}
这个时候如果使用:
<select id="getUser2ById" resultType="com.moyok.ajax.bean.User2">
select * from user where id = #{id};
</select>
的方式进行查询时,查出来的结果为null
如果实体类的结构如下:
public class User2 {
Integer id1;
String username1, password1, email;
}
那么查出来的结果为:
mapper.getUser2ById(12) = User2(id1=null, username1=null, password1=null, email=songxiaoxu2002@qqq.com)
这是因为只有email属性和表中的email字段对应上
解决方式1:给字段取别名
<select id="getUser2ById" resultType="com.moyok.ajax.bean.User2">
select id id1, username username1, password password1, email from user where id = #{id};
</select>
解决方式2:
- 前提是数据库中的表的字段按照
单词_单词的方式进行命名的 - 实体类中的属性是按照小驼峰规则进行命名的
在核心配置文件中的<configuration>标签中,添加以下标签
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
解决方法3:
-
针对于任何情况,使用
resultMap -
在
Mapper.xml文件中添加一个<resultMap></resultMap>标签,并给这个标签指定id属性和type属性(全类名) -
在
<resultMap>标签内,可以使用<id>标签对主键进行映射,使用<result>标签对其他属性进行映射 -
在相关的
<select>标签中添加resultMap属性,属性值为<resultMap>标签的id属性 -
使用这种方式可以只给需要的键进行映射
-
<select id="getUser2ById" resultMap="user2ResultMap"> select * from user where id = #{id}; </select> -
<resultMap id="user2ResultMap" type="com.moyok.ajax.bean.User2"> <!-- 用来映射主键--> <!-- <id property="类中的属性" column="表中的字段名" />--> <id property="id1" column="id" /> <!-- 针对普通字段的映射--> <!-- <result property="类中的属性" column="表中的字段名" />--> <result property="username1" column="username" /> <result property="password1" column="password" /> <result property="email" column="email" /> </resultMap>
多对一映射
应用于多表查询,例如
- 一个员工对应一个部门
- 有两个表:
- 员工表
- 部门表
多对一只需要创建一所对应的对象,针对上例,只需要在员工实体类中创建一个部门的成员变量
例如,现在有两张表:
学生表
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(15) | NO | | NULL | |
| department | varchar(20) | NO | MUL | NULL | |
| sex | varchar(4) | NO | | NULL | |
+------------+-------------+------+-----+---------+----------------+
成绩表:
+-------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------------+------+-----+---------+-------+
| cno | int | NO | PRI | NULL | |
| stuNo | int | NO | PRI | NULL | |
| score | decimal(10,1) | YES | | NULL | |
+-------+---------------+------+-----+---------+-------+
查询的SQL命令为
select * from student join score s on student.id = s.stuNo;
多对一也有三种解决方案:
-
方式1:级联属性赋值,这种方式最简单,但不是最常用的方式
-
此时的学生实体类中已经声明了成绩的成员变量
public class Student { public Integer id; public String name, department, sex; Score score; } -
此时仍使用
resultMap -
将实体成员变量
score.xxx的各个属性一一对表中的字段进行映射 -
<resultMap id="queryScoreForOne" type="com.moyok.ajax.bean.Student"> <result property="score.cno" column="cno" /> <result property="score.stuNo" column="stuNo" /> <result property="score.score" column="score" /> </resultMap> <select id="getStudentScoreById" resultMap="queryScoreForOne"> select * from student join score s on student.id = s.stuNo where student.id = #{id}; </select> -
这时候查出来的值就是正常的
-
studentMapper.getStudentScoreById(1016) = Student(id=1016, name=王红, department=计算机系, sex=女, score=Score(cno=2, stuNo=1016, score=78.5)) -
Student getStudentScoreById(Integer id);
-
-
方式2:
-
依旧是使用
<resultMap>标签 -
需要在
<resultMap>标签中针对score属性使用<association></association>标签association中文为协会,读音为əˌsoʊsiˈeɪʃn- 这个标签的
property属性的值为相应的类对象,在这里代表socre type属性为这个类对象的全类名- 在
<association></association>标签中,就可以写id、result相应的标签了,其中的property之类的含义和之前的都相同
-
使用这种方式必须要把所有的属性和列名映射都要写上
-
<resultMap id="queryScoreForOne" type="com.moyok.ajax.bean.Student"> <id property="id" column="id"/> <result property="name" column="name"/> <result property="department" column="department"/> <result property="sex" column="sex"/> <association property="score" javaType="com.moyok.ajax.bean.Score"> <id property="cno" column="cno"/> <result property="score" column="score"/> <result property="stuNo" column="stuNo"/> </association> </resultMap>
-
-
方式3:
- 也是使用
association标签 - 使用分步查询
- 也是使用
懒加载
这里,抽空补
一对多
一对多相当于多对一反过来的
同时也是应用于多表查询,例如
- 一个员工对应一个部门
- 有两个表:
- 员工表
- 部门表
多对一表示为在部门表中查出每个部门所有员工
这个时候的解决方案是:在部门实体类中放一个List<员工类>
还是以学生成绩表和学生表为例,此时部门实体类中的内容为
public class Score {
public Integer cno, stuNo;
public Double score;
public List<Student> list;
}
<resultMap id="queryScoreById" type="com.moyok.ajax.bean.Score">
<id property="cno" column="cno"/>
<result property="score" column="score"/>
<result property="stuNo" column="stuNo"/>
<collection property="list" ofType="com.moyok.ajax.bean.Student">
<id property="id" column="id"/>
<result property="name" column="name"/>
<result property="department" column="department"/>
<result property="sex" column="sex"/>
</collection>
</resultMap>
<select id="getScoreByStudentId" resultMap="queryScoreById">
select * from score left join student s on score.stuNo = s.id where s.id = #{id};
</select>
动态SQL
根据特定的条件进行拼装SQL语句,如果表达式为true,标签中的内容会执行,否则不会执行,符合条件就拼接,不符合条件不拼接
if标签
并且:and
用法:在where后先加一个1 = 1,用来作为一个恒成立的条件,防止特殊情况崩溃
以下代码表示name不为空或者不为空字符串时拼接以下的SQL
<select id="getStudentsCondition" resultType="com.moyok.ajax.bean.Student">
select * from student where 1 = 1
<if test="name != null and name != ''">
and name = #{namme}
</if>
</select>
List<Student> getStudentsCondition(String name);
where标签
有上例发现,每次都必须写一个where 1 = 1 ,如果不写这个可能会导致报错
针对这个问题的解决方案是:去掉where 1 = 1,写一个<where></where>,将<if></if>写到里边,test="条件"
<select id="getStudentsCondition" resultType="com.moyok.ajax.bean.Student">
select * from student
<where>
<if test="name != null and name != ''">
and name = #{namme}
</if>
</where>
</select>
如果where标签中有内容成立,将会自动添加where关键字,并将前边多余的and、or去掉,例如上面的例子,如果不去掉and的话,结果为select * from student where and name = #{名称},写在后边的and不会去掉
trim标签
trim中文为修剪
可以将where标签换为trim
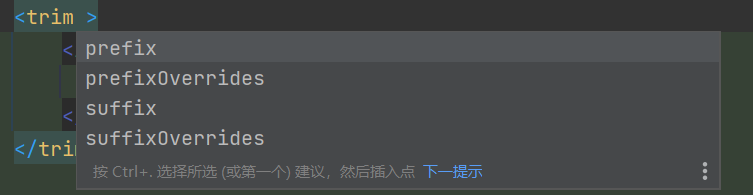
属性有:
prefix,前缀,将trim前面添加指定内容prefixOverrides,前缀重写,将trim前面去掉指定内容suffix,后缀,将trim后面添加指定内容suffixOverrides,后缀重写,将trim后面去掉指定内容
因为这个时候把where去掉了,所以前缀的值要为where
如果要去掉/添加多个内容,可以写为内容1|内容2
<select id="getStudentsCondition" resultType="com.moyok.ajax.bean.Student">
select * from student
<trim prefix="where" prefixOverrides="and|or" suffix=";" suffixOverrides="and|or">
<if test="name != null and name != ''">
and name = #{namme} and
</if>
</trim>
</select>
例如上例就是针对前后都有and/or的解决方案
如果trim中没有任何符合条件的,那么这个时候SQL语句后边将不会加任何内容
choose when otherwise标签
otherwise中文为除此之外,相当于if...else if...else
<choose是一个父标签,when、otherwise都需要写在里边,when至少要有一个otherwise可以没有
<select id="getStudentsCondition" resultType="com.moyok.ajax.bean.Student">
select * from student
<choose>
<when test="name == null">
where id = 1001;
</when>
<when test="name == ''">
where id = 1002;
</when>
<otherwise>
where name = #{name};
</otherwise>
</choose>
</select>
choose标签可以放到where或者trim标签中的
<select id="getStudentsCondition" resultType="com.moyok.ajax.bean.Student">
select * from student
<where>
<choose>
<when test="name == null">
id = 1001
</when>
<when test="name == ''">
id = 1002
</when>
<otherwise>
name = #{name}
</otherwise>
</choose>
</where>
</select>
<select id="getStudentsCondition" resultType="com.moyok.ajax.bean.Student">
select * from student
<trim prefix="where" prefixOverrides="and|or" suffixOverrides="and|or" suffix=";">
<choose>
<when test="name == null">
id = 1001
</when>
<when test="name == ''">
id = 1002
</when>
<otherwise>
name = #{name}
</otherwise>
</choose>
</trim>
</select>
foreach标签
如果传递进来的参数是一个数组或者集合,可以使用这个标签进行遍历
int batchDelete(Integer[] arr);
<delete id="batchDelete">
delete from stucourse where cno in
(
<foreach collection="arr" item="it" separator=",">
#{it}
</foreach>
)
</delete>
studentMapper.batchDelete(new Integer[]{1, 6, 21})
separator中文为分离器,读音为ˈsepəreɪtər,会在每个元素的最后添加分隔符
以上相当于delete from stucourse where cno in (1, 6, 21)
collection指定要遍历的数组/集合
item相当于循环遍历的变量
open属性:在数据开启之前添加的内容
close属性:在数据结束之前添加的内容
还可以将以上内容优化为:
<delete id="batchDelete">
delete from stucourse where cno in
<foreach collection="arr" item="it" separator="," open="(" close=")">
#{it}
</foreach>
</delete>
例如select * from student where id in (1001, 1002, 1003, 1004);可以使用List+or表示为:
List<Student> getStudentByIds(List<Integer> ids);
studentMapper.getStudentByIds(new ArrayList<>(){
{
add(1001);
add(1002);
add(1003);
add(1004);
}
}).forEach(System.out::println);
<select id="getStudentByIds" resultType="com.moyok.ajax.bean.Student">
select * from student
<foreach collection="ids" item="item" open="where id = " separator="or id = ">
#{item}
</foreach>
</select>
批量插入数据
MySQL一次性插入多条数据的命令是
insert into 表名(字段列表) values (数据列表1), ..., (数据列表n);
int batchInsertStudent(List<Student> users);
<insert id="batchInsertStudent">
insert into student(name, department, sex) values
<foreach collection="users" item="item" separator="," >
(#{item.name}, #{item.department}, #{item.sex})
</foreach>
</insert>
System.out.println(studentMapper.batchInsertStudent(new ArrayList<Student>() {
{
add(new Student("李丹爱", "经济系", "女"));
add(new Student("任健康", "计算机系", "女"));
add(new Student("李爱的", "设计系", "女"));
}
}));
sqlSession.commit();
sql标签
可以将一些常用的SQL语句片段放到<sql></sql>中,用id属性指定一个id
使用<include refid="id" />在需要的位置引入
例如:
<sql id="studentsql">
name, sex
</sql>
<select id="getStudents" resultType="com.moyok.ajax.bean.Student">
select <include refid="studentsql" /> from student;
</select>
相当于select username, sex from student;
Mybatis的缓存
分为一级缓存和二级缓存
一级缓存
缓存是指缓存查询过的数据
一级缓存是SqlSession级别的,即通过同一个SqlSession查询的数据将会被缓存,下次查询相同的数据时会从缓存中获取,不会再访问数据库,缓存也会失效的:
- 不同的
SqlSession有不同的一级缓存 - 同一个
SqlSession,但查询条件不同 - 同一个
SqlSession,两次查询期间经过了增删改操作- 只要经过了增删改操作,就会清除一次缓存
- 同一个
SqlSession,两次查询期间清空了缓存sqlSession.clearCache();
一级缓存默认开启的
测试:如果进行打日志的方式进行查询输出时,会发现两个相同的查询语句只输出了一个SQL语句
SqlSession级别:
-
SqlSession sqlSession = new SqlSessionFactoryBuilder() .build(Resources.getResourceAsStream("mybatis-config.xml")) .openSession(); StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class); ScoreMapper scoreMapper = sqlSession.getMapper(ScoreMapper.class); -
代码中的
studentMapper和scoreMapper使用共同的一级缓存,因为这两个对象都是由同一个SqlSession生成的(即便两者不是同一个对象)
二级缓存
二级缓存是SqlSessionFactory级别的,需要手动开启
- 核心配置文件中,设置
cacheEnabled="true",这个是默认开启的,无需再手动设置 - 映射文件中的
<mapper></mapper>标签中只需要加上<catch />即可开启 - 二级缓存必须在
SqlSession关闭或者提交之后才有效- 当没有关闭或者提交时,缓存只能存在于一级缓存中
- 查询的数据所转换的实体类类型必须要实现可序列化接口
Serializable
二级缓存失效的情况:
- 两次查询执行了任意的增删改,会使得一级缓存和二级缓存同时失效
sqlSession.clearCache();只对一级缓存有效
二级缓存可以配置的:
-
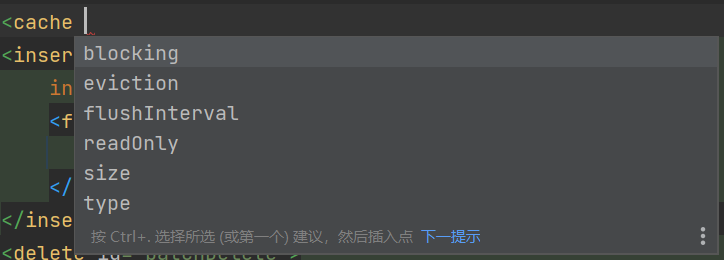
-

-
缓存是缓存到内存中的所以不能够无限制的进行缓存
缓存的查询顺序
先查询二级缓存,因为范围最大,如果有,就直接拿来用
如果二级缓存中没有,再查询一级缓存
如果一级缓存也没有,最后再查询数据库
整合缓存
可以整合其他的第三方缓存,例如EHCache
逆向工程
正向工程:先创建实体类,由框架根据实体类生成数据库表
逆向工程:先创建数据库表,由框架负责数据库表,反向生成:
Java实体类Mapper接口Mapper映射文件
依赖于许多插件,可以在安装插件后在插件列表运行
步骤:
- 准备依赖
- 创建逆向工程配置文件,文件名固定为
generatorConfig.xml - 双击插件即可运行
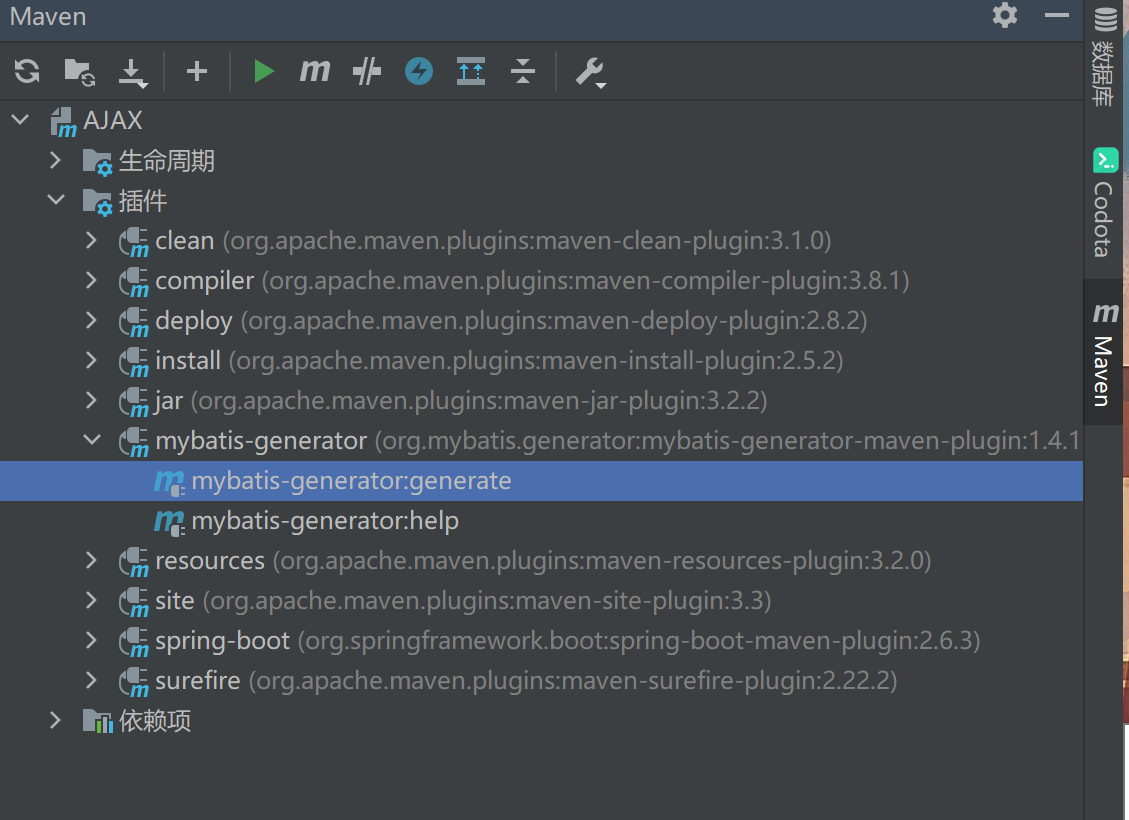
引入的依赖(放到plugins)标签内
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.4.1</version>
<!-- 插件的依赖 -->
<dependencies>
<!-- 逆向工程的核心依赖 -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.4.1</version>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>5.0.1</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
</dependencies>
</plugin>
逆向工程配置文件:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!-- 配置表信息内容体 targetRuntime采用 MyBatis3Simple的版本,只有简单的增删改查 -->
<!-- 配置表信息内容体 targetRuntime采用 MyBatis3的版本,带有条件的增删改查 -->
<context id="tables" targetRuntime="MyBatis3Simple">
<!-- 抑制生成注释 由于生成的注释都是英文的 所以可以不让他生成 -->
<commentGenerator>
<property name="suppressAllComments" value="true"/>
</commentGenerator>
<!-- 配置数据库连接信息-->
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/test"
userId="root"
password="密码">
<!-- 解决Mysql8.0生成重复的问题-->
<property name="nullCatalogMeansCurrent" value="true" />
</jdbcConnection>
<!-- 生成实体model类 第一个指向的是model类的包名 第二个路径是放在什么地方 -->
<javaModelGenerator targetPackage="com.moyok.ajax.beans"
targetProject="src/main/java">
<!-- 是否能够使用子包,这个时候每个.都代表一个包,否则为false是对应的是一个目录-->
<property name="enableSubPackages" value="true"/>
<!-- 去掉字符串前的空格,字段名前后如果有空格,那么一并去掉-->
<property name="trimStrings" value="true"/>
</javaModelGenerator>
<!-- 生成mabatis的mapper.xml文件 第一个指向的是 包名 第二个生成的文件放的路径-->
<sqlMapGenerator targetPackage="com.moyok.ajax.mappers"
targetProject="src/main/resources">
<!-- 使用子包-->
<property name="enableSubPackages" value="true"/>
</sqlMapGenerator>
<!-- 生成mybatis的mapper接口类核心文件 指定mapper接口类的包名 生成mapper接口放在什么路径-->
<javaClientGenerator type="XMLMAPPER"
targetPackage="com.moyok.ajax.mappers"
targetProject="src/main/java">
<property name="enableSubPackages" value="true"/>
</javaClientGenerator>
<!-- 数据库表明对应的Java模型类名-->
<!-- 根据表生成的实体类的名称-->
<table tableName="examstudent" domainObjectName="ExamStudent"/>
<table tableName="info" domainObjectName="Info"/>
<table tableName="money" domainObjectName="Money"/>
<table tableName="user" domainObjectName="User"/>
<table tableName="user_table" domainObjectName="UserTable"/>
</context>
</generatorConfiguration>
如果使用targetRuntime="MyBatis3",那么此时创建出的是带有条件查询的接口,并且在生成的类中分为实体类和实体类Example,实体类Example是用来作条件查询的
在Mapper接口中也有许多带有Example后缀的方法,这些方法是按照一定的条件进行查询的
@Test
void test3() throws IOException {
SqlSession sqlSession = new SqlSessionFactoryBuilder()
.build(Resources.getResourceAsStream("Mybatis-config.xml"))
.openSession();
MoneyMapper mapper = sqlSession.getMapper(MoneyMapper.class);
// for (int i = 0; i < 15; i++) {
// System.out.println(mapper.insert(new Money() {
// {
// setUsername(UUID.randomUUID().toString().split("-")[0]);
// setAmount(new Random().nextInt(100000));
// }
// }));
// }
// sqlSession.commit();
MoneyExample moneyExample = new MoneyExample();
// 排序规则
moneyExample.setOrderByClause("amount");
/*
以下都针对于and运算符
*/
MoneyExample.Criteria criteria = moneyExample.createCriteria();
// 相当于select * from money where amount >= 1137 and amount <= 86060
criteria.andAmountGreaterThanOrEqualTo(1137);
criteria.andAmountLessThanOrEqualTo(86060);
// 某个属性值范围
// criteria.andAmountBetween(1000, 10000);
// 字符串的like
// criteria.andUsernameLike("%d%");
// 属性小于
// criteria.andAmountLessThan(3000);
// 属性值等于
// criteria.andAmountEqualTo(1000);
// in (值1, ..., 值n)
// criteria.andAmountIn(Arrays.asList(1000, 1137, 86060));
// 大于某值
// criteria.andAmountGreaterThan(1000);
// 小于等于
// criteria.andAmountLessThanOrEqualTo(1000);
// 大于等于
// criteria.andAmountGreaterThanOrEqualTo(1000);
// 非空
// criteria.andAmountIsNotNull()
// 通过这个方法创建出来的都是or
// 以下两句相当于select * from money where amount <= 1137 or amount >= 86060
// moneyExample.or().andAmountLessThanOrEqualTo(1137);
// moneyExample.or().andAmountGreaterThanOrEqualTo(86060);
mapper.selectByExample(moneyExample).forEach(System.out::println);
}
所自动生成的方法中有两个插入方法,一个是insert(对象)和insertSelective(对象)
-
第一个是普通添加,例如如果有属性是空的,也会执行向数据库添加的操作
-
第二个添加为选择性添加,如果有的字段是空,将不会将这个属性添加,也就是只选择不为空的
-
例如
-
Money money = new Money(); money.setAmount(100); money.setUsername(null); // 普通插入 mapper.insert(money); sqlSession.commit(); -
表的结构为:
-
+----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | username | varchar(20) | YES | | 未设置 | | | amount | int | NO | | NULL | | +----------+-------------+------+-----+---------+----------------+ -
插入结果为
+----+----------+--------+ | id | username | amount | +----+----------+--------+ | 19 | NULL | 100 | +----+----------+--------+ -
当使用以下方式插入时:
-
Money money = new Money(); money.setAmount(1000); money.setUsername(null); mapper.insertSelective(money); sqlSession.commit(); -
结果为
+----+----------+--------+ | id | username | amount | +----+----------+--------+ | 20 | 未设置 | 1000 | +----+----------+--------+ -
由此得知:
-
第一种方式是无论某个属性是否为空,都按照值插入
-
第二种方式时只插入值不为空的字段,由
username字段的默认值是未设置可得知 -
第一种方式的插入语句为:
insert into money(id, username, amount) values(null, null, 1000); -
第二种方式插入的语句为:
insert into money(amount) values(1000);
-
-
底层的源码使用的是动态SQL
分页插件
引入依赖:
<!-- https://mvnrepository.com/artifact/com.github.pagehelper/pagehelper -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.3.0</version>
</dependency>
在核心配置文件中配置分页插件:
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor"/>
</plugins>
简单用法:
配置好插件之后,直接调用以下方法(页码从1开始)
PageHelper.startPage(页码, 每页个数);
接下来直接调用响应的方法获取一个结果集即可,不需要其他任何的额外用法
例如
PageHelper.startPage(2, 10);
mapper.selectByExample(new MoneyExample()).forEach(System.out::println);
还可以进行排序:
PageHelper.startPage(2, 10);
PageHelper.orderBy("amount desc");
mapper.selectByExample(new MoneyExample()).forEach(System.out::println);
根据官方文档可得知:只有紧跟在PageHelper.startPage方法后的第一个Mybatis的**查询(Select)**方法会被分页。
PageHelper.startPage(页码, 每页个数)方法是有返回值的,返回值为Page<T>,数据结构形如:
PageHelper.startPage(1, 20);
Page{count=true, pageNum=1, pageSize=20, startRow=0, endRow=20, total=0, pages=0, reasonable=null, pageSizeZero=null}[]
PageHelper.startPage(2, 20);
Page{count=true, pageNum=2, pageSize=20, startRow=20, endRow=40, total=0, pages=0, reasonable=null, pageSizeZero=null}[]
count:布尔值,代表查询了总的页数pageNum:当前页的页码pageSize:每页显示的条数startRow:从第几行开始endRow:到第几行结束total:总的数据的条数pages:总的页数resonable:中文为合理的pageSizeZero:hasPreviousPage:布尔值,代表有无上一页hasNextPage:布尔值,代表有下一页navigatePages:布尔值,代表手动指定的页数
可能使用这种方式输出的总页数和总的记录的条数不正常,所以可以使用PageInfo<实体类>,这个类的构造方法中可以填入一个List,可以把List类型的结果集传进去,可以在这个实例中正确的获取到总的页数之类的信息
例如:
PageHelper.startPage(2, 20);
List<Money> list = mapper.selectByExample(null);
PageInfo<Money> pageInfo = new PageInfo<>(list);
System.out.println("pageInfo = " + pageInfo);
list.forEach(System.out::println);
结果为:
pageInfo = PageInfo{pageNum=2, pageSize=20, size=20, startRow=21, endRow=40, total=125, pages=7,
list=Page{count=true, pageNum=2, pageSize=20, startRow=20, endRow=40, total=125, pages=7, reasonable=false, pageSizeZero=false}[Money(id=22, username=f334e165, amount=36536), Money(id=23, username=34f8df7d, amount=92214), Money(id=24, username=d80af0e2, amount=92923), Money(id=25, username=32bd193c, amount=50816), Money(id=26, username=7e442094, amount=87897), Money(id=27, username=b170b9e3, amount=24051), Money(id=28, username=f8690ec4, amount=53710), Money(id=29, username=35180779, amount=76146), Money(id=30, username=2c144814, amount=75455), Money(id=31, username=aadf7988, amount=74780), Money(id=32, username=6d66891f, amount=95957), Money(id=33, username=ba53e3e6, amount=32910), Money(id=34, username=95114415, amount=13559), Money(id=35, username=8c98befb, amount=72352), Money(id=36, username=b611dc3e, amount=16594), Money(id=37, username=a9dff42d, amount=514), Money(id=38, username=8fbd697a, amount=46973), Money(id=39, username=ca21a8c2, amount=75406), Money(id=40, username=753dad2b, amount=3561), Money(id=41, username=bec4c6db, amount=81787)], prePage=1, nextPage=3, isFirstPage=false, isLastPage=false, hasPreviousPage=true, hasNextPage=true, navigatePages=8, navigateFirstPage=1, navigateLastPage=7, navigatepageNums=[1, 2, 3, 4, 5, 6, 7]}
可以最后返回这个对象到页面上,
这个类还有另外一个构造方法:List, 数字
-
这个数字代表要返回到页面上导航页码的个数,最好写一个奇数
-
例如上例返回结果中有一个参数
navigatepageNums=[1, 2, 3, 4, 5, 6, 7],代表返回的导航页码-
例如,当
PageHelper.startPage(3, 20);时,总页数为7页- 如果这个时候
new PageInfo<>(list, 3);,那么最后的导航页码结果为[2, 3, 4]
- 如果
new PageInfo<>(list, 5);时navigatepageNums=[1, 2, 3, 4, 5]
- 如果这个时候
-
很显然,这个时候目标页码
3处于一个中间位置,但如果是偶数,两边就不会平衡了
-
Spring Boot整合MyBatis
更换依赖:
<!-- https://mvnrepository.com/artifact/org.mybatis.spring.boot/mybatis-spring-boot-starter -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
配置模式
starter将会自动配置好SqlSessionFactory,数据源使用的是容器中的数据源
也可以不给相应的接口添加@Mapper注解,可以在Application类或者配置类上添加@MapperScan("包名")注解,用来指定这个包下所有的接口都属于Mapper
会自动查找标注了@Mapper注解的接口
- 需要在
Mapper所对应的接口上添加@Mapper注解 - 如果映射文件
.xml没有和Mapper接口所在的包相同,需要在application.yml中手动指定映射文件作在的位置
mybatis:
# config-location: classpath:配置文件路径+名称
# 如果不在同一个包下,需要手动指定Mapper.xml文件位置,*表示匹配所有的xml
mapper-locations: classpath:mappers/*.xml
# 开启驼峰匹配
# configuration:
# map-underscore-to-camel-case: true
在用到的位置,声明成员变量,为其添加@Autowired注解
@Autowired
MoneyMapper mapper;
@Autowired
User2Mapper mapper2;
@RequestMapping("/mybatis")
public List<Money> test1() {
System.out.println("mapper2.getCount() = " + mapper2.getCount());
return mapper.selectByExample(null);
}
如果映射文件在同一包下,无需任何配置
驼峰规则、包名映射可以在配置文件中打开
凡是在全局配置文件.xml的配置,都可以在application.yml配置
注解配置混合
注解和配置文件可以混合
@Mapper
public interface User2Mapper {
int getCount();
@Select("select * from user")
List<User> getAllUsers();
@Select("select * from user where id = #{id}")
User getUserById(Integer id);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.moyok.ajax.mappers.User2Mapper">
<select id="getCount" resultType="java.lang.Integer">
select count(*) from user;
</select>
</mapper>
Q.E.D.

