

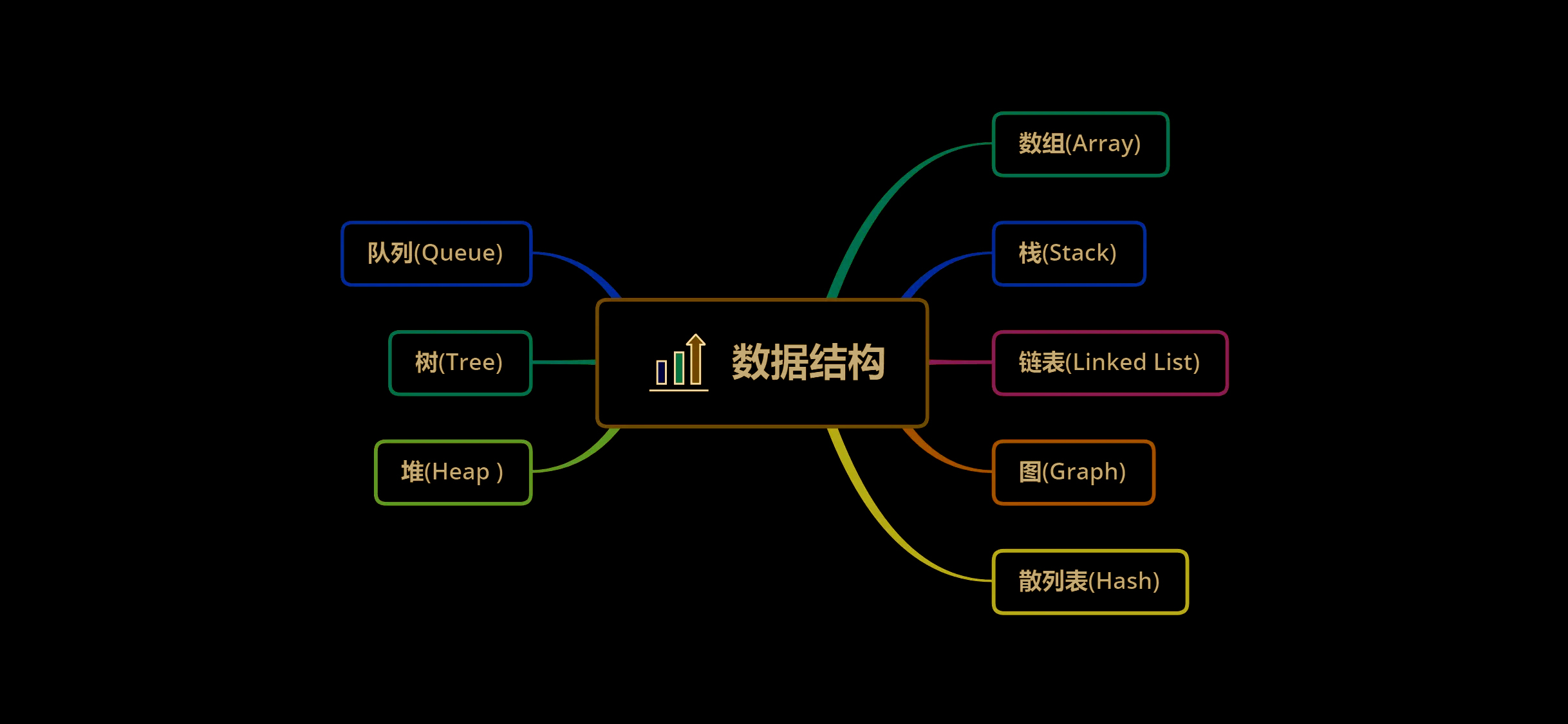

树(Tree)

树是一种逻辑结构
树是n个非空结点的有限集合,n=0时称为空树
非空树需满足:
- 有且只有一个称为根的结点
- 当n>1时,其余结点可分为m(m>0)个互不相交的有限集合,每个集合的本身也是一棵树,称为根结点的子树
- 树可以看做是递归的数据结构
- 每个结点都有一个前驱结点,有0个或多个后继结点
- n个结点的树中只有n-1条边
术语
###祖先结点和子孙结点
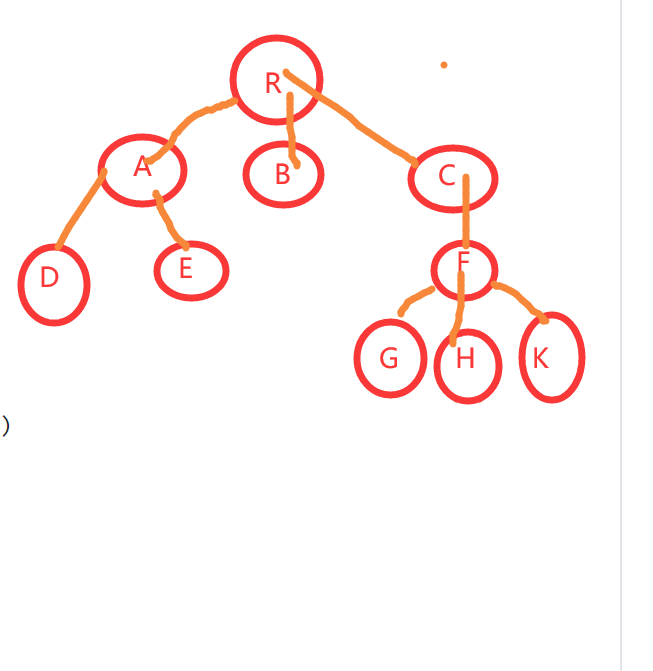
例如上图的H,若要从A到H,必定要经过A-B-E,此时H前边的任意一个结点都被称为祖先结点,其他结点之后的可以成为子孙结点
双亲结点和孩子结点
上图中的H在E之下,H被称为E的孩子结点,E被称为H的双亲结点
兄弟结点
具有相同的双亲结点的结点可以并称为兄弟结点
度
####结点的度
树中一个结点的子结点的个数称为该结点的度
子结点为该结点的下一个结点
例如 B的子结点(孩子的个数)的个数为2,仅包含E和F
树的度
树的最大度为所有结点的最大度
分支结点和叶子结点
度>0的节点称为分支结点或非终端结点,度为0的节点称为叶子结点或终端结点
除根结点外,分支结点也被称为内部节点
结点
结点的层次、高度、深度
层次:根节点定义为第一层,以此类推,直到第N层
高度:与层次相反,从最低一层向上数
深度:从上往下输,与层次一致
树的高度或者是深度为结点的最大高度或深度
有序树和无序树
当两个结点交换位置后,如果这个树是无序树,那交换后与交换前是同一种树,如果是有序树,交换后是两种树
路径
经过的结点,不包含边
上图从A—H的路径为A-B-E-H
路径长度是经过边的个数
森林
n(n>0)棵互不相交的树的集合
如上图,把A去掉,其中BCD就构成森林
树的性质
-
树的结点数等于所有结点的度数+1
-
度为m的树中第i层,其上最多有
$$
个结点(i>=1)
$$
例如第一层有1个结点,那么该层的最多结点数为
$$
{1}{1-1}=1个结点
$$
第二层有m个结点,那么该层最多有
$$
=m个结点
$$
因为第三层有m个结点,每个节点有m个子节点,那么
$$=m^2个结点
$$ -
高度为h的m叉树,至多有
$$
\frac{(m^h-1)}{(m-1)}个结点
$$ -
具有n个结点的m叉树的最小高度为
$$
\log_{[n(m-1)+1]}
$$
树的存储结构
双亲表示法
实现:利用结构数组,存放树的结点,每个结点包含两个域
数据域:包含数据信息
双亲域:存放双亲结点的位置
例如
| 数组下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 数据域 | R | A | B | C | D | E | F | G | H | K |
| 双亲域 | -1 | 0 | 0 | 0 | 1 | 1 | 3 | 6 | 6 | 6 |
结构原型
//结点结构
typedef struct
{
int data;
int parents;
}tree;
//树结构
typedef struct
{
tree node[maxSize];
int pos,n;//存储当前位置和个数
}pTree;
特点是找双亲容易,找孩子难
孩子链表
把每个结点的孩子结点排列起来,看成一个线性表,n个结点有n个孩子链表(叶子的孩子链表为空),n个链表的头指针构成一个线性表,用顺序表存储,即将每个孩子结点都看作是双亲结点,只不过是有的没有孩子结点
每个链表的头指针就是它的双亲结点
//单链表的结构
typedef struct
{
int child;//孩子结点的下标
struct chNode *next;//下一个孩子结点的指针
}chNode;
//每个结点存放的数据元素
typedef struct
{
elementType data;
struct chNode *childFirst;//头指针
}pNode;
//树
typedef struct
{
pNode node[maxSize];
int r,n;//当前位置和总的个数
}tree;
特点:找孩子容易,找双亲难
孩子兄弟表示法(二叉链表表示法或者二叉树表示法)
使用二叉链表存储,链表中包含两个指针域,一个指针域表示它的第一个孩子,另一个表示它的下一个兄弟结点
结构原型
typedef struct
{
elementType data;
struct tree *firstChild,*nextNohd;
}tree;
对于每一个结点,一个结点除了它的第一孩子就是他的右兄弟。
如果一个结点想要找他的孩子,则先找它的左侧结点,在继续找它的右侧结点,直到为空
树和二叉树的转换
基于孩子兄弟表示法(把兄弟当儿子看)
树和二叉树都可以用二叉链表做存储结构,以二叉链表作为媒介可以导出树与二叉树的关系
给定一棵树,都能找到唯一的与之对应的二叉树,第一个儿子在左子树,兄弟在右子树
规律
兄弟结点是右孩子,从而没有了与其双亲结点的连线
做法
- 加线:兄弟之间加一条线
- 抹线:对于每个结点,除了左孩子之外,去掉它和它其余孩子之间的连线
- 旋转:以树(每个子树)的根节点为轴心,将整棵树顺时针旋转45度
- 口诀:兄弟相连留长子
逆向操作
- 加线:若p结点的结点是双亲结点的左孩子,则将p的右孩子的右孩子的...右孩子 沿线找到所有的右孩子都与p的双亲节点连接起来
- 抹线:将之前所有双亲与右孩子的连线抹掉
- 调整:将结点按层次排列,形成树的结构
- 口诀:左孩右右连双亲,去掉原来右孩线
森林转为二叉树(二叉树和多棵树的关系)
- 将每棵树转换成二叉树
- 将树的根节点用线相连
- 以第一棵树的根节点为二叉树的根,以根结点为轴心,顺时针旋转,构成二叉树的结构
- 口诀:树变二叉根相连
二叉树转为森林
- 抹线:将二叉树的根节点右侧的以及右侧的右侧的线抹掉,使其变成若干棵孤立的二叉树
- 还原:将孤立的二叉树还原成树
- 口诀:去掉所有右孩线,孤立二叉再还原
树的遍历方式(三种)
先序遍历、后序遍历、层次遍历
先序遍历
如果树不为空,先访问根节点,再依次访问各个子树
后序遍历
与二叉树的后续遍历类似
层序遍历
与二叉树的方式一致
森林的遍历
森林可以看做由三部分构成的
- 森林中第一棵树的根节点
- 森林中的第一棵树的子树森林
- 森林中其他树构成的森林
先序遍历
若森林不为空,则
- 访问森林第一棵树的根节点
- 先序遍历森林中第一棵树的子树森林
- 先序遍历森林中(除第一棵树之外)其余树构成的森林
- 人话:从左至右对森林中的每一棵树进行先根遍历
后序遍历
若森林不为空,则
- 中序遍历森林中第一棵树的子树森林
- 访问第一棵树的根节点
- 中序遍历其他森林
- 人话:从左至右对森林中的每一棵树进行后根遍历
哈夫曼树
#include <stdio.h>
#include <stdlib.h>
typedef int elementType;
typedef struct tree
{
elementType data;
struct tree *l, *r, *parents;
} tree;
tree *set[100];
int n;
int set2[999];
void sort()//排序函数,按照降序进行排序,以便于取最小和次小值
{
for (int i = 0; i < n; i++)
for (int j = i + 1; j < n; j++)
{
if (set[i]->data < set[j]->data)
{
tree *t = set[i];
set[i] = set[j];
set[j] = t;
}
}
}
void create()//创建哈夫曼树
{
while (n != 1)
{
tree *a = set[n - 1], *b = set[n - 2];//取最小和次小的
tree *p = (tree *) malloc(sizeof(tree));//用来存储新结点
p->data = a->data + b->data;//新跟结点是左右子树的值相加
p->l = a;//左孩子
p->r = b;//右孩子
p->parents = NULL;//父母设为空
b->parents = a->parents = p;//让它的父母指向p
n--;
set[n - 1] = p;
sort();
}
}
void print(tree *t)
{
if (t == NULL)
return;
printf("%d->", t->data);
print(t->l);
print(t->r);
}
void findElement(tree *t, int value, tree **find)
{
if (t == NULL)
return;
if (t->data == value && t->r == NULL && t->l == NULL)
(*find) = t;
if (t->l && t->r)
{
findElement(t->l, value, find);
findElement(t->r, value, find);
}
}
void findParents(tree *t)
{
if (t->parents == NULL)
return;
if (t->parents->l->data == t->data)
printf("0");
else
printf("1");
findParents(t->parents);
}
int main()
{
int nn;
printf("输入元素个数:");
scanf("%d", &n);
nn = n;
for (int i = 0; i < n; i++)
{
set[i] = (tree *) malloc(sizeof(tree));
scanf("%d", &set[i]->data);
set2[i] = set[i]->data;
set[i]->parents = set[i]->l = set[i]->r = NULL;
}
sort();
create();
printf("先序遍历结果:");
print(set[0]);
printf("\b\b ");
printf("\n---编码后----\n");
for (int i = 0; i < nn; i++)
{
tree *find = NULL;
findElement(set[0], set2[i], &find);
if (find == NULL)
printf("未找到");
else
{
printf("%d:", set2[i]);
findParents(find);
printf("\n");
}
}
return 0;
}
哈夫曼编码
生成哈夫曼树后,编码为根节点到这个叶子结点的路径,左为0,右为1
路径长度为经过的边的个数
哈夫曼树的带权路径长度=每个频度或者本身的值 * 路径长度之和
二叉树
是树形结构一种,是一种逻辑结构,规定每个结点最多有两个孩子结点
两个孩子结点名称不同,左边的称为左孩子,右边的称为右孩子
二叉树可以为空,$$n$$个结点的二叉树最多有$$\frac{(2n)!}{n!(n+1)!}$$种形态
满二叉树

上图就是一个满二叉树
所有的分支结点都存在左子树和右子树,所有的叶子结点都在同一层上(最后一层)
$$满二叉树的结点的个数={2}^{层数}-1$$
特点
$$
一个编号为i的结点的左孩子的编号=2\times i,右孩字的编号=2\times i+1
$$
完全二叉树

上图是一个完全二叉树
一个高度为h的二叉树与一个高度为h的满二叉树上的结点一一对应,那么这个树就是完全二叉树。
满二叉树一定是一棵完全二叉树
完全二叉树的叶子结点仅出现在最后一层和倒数第二层,并且最后一层的叶子结点从左至右一一连续
性质
$$
1.在二叉树的第i层最多有2^个结点,i需>=i
$$
在此图中,可以应用此性质
$$
2.深度为k的二叉树,最多有2^k-1个结点
$$
上图满二叉树中,深度为4,总结点个数为15个,利用此公式也可以算出
$$
3.二叉树中,如果终端结点(叶子结点即度为0的结点)的个数为n_0,度为2的结点的个数为n_2,则终端结点n_0=n_2+1
$$
即终端(叶子)结点的个数=度为2的结点的个数+1
$$
4.具有n个结点的完全二叉树的深度为log_2n+1取下界(取整数)
$$
$$
深度为k的满二叉树的结点n的个数为2^-1,就代表结点为n二叉树的深度为
$$
$$
log_2(n+1),因为完全二叉树的节点个数小于等于2,又大于2-1个
$$
$$
其中2^-1为上一层的结点个数,因此完全二叉树的深度为log_2n+1取下界
$$
- 对于一棵有n个结点的完全二叉树,深度为int(log2n+1),并进行编号,对于任意结点i(1<=i<=n)有:
- 如果i=1,则结点i是二叉树的根。如果i>1,则其双亲结点是int(i/2)
- 如果2*i>n,则结点i无左孩子,此时的结点i为叶子结点。如果2 *i<=n,则左孩子结点就是2 *i
- 如果2*i+1>n,则结点i无右孩子,否则,右孩子为2i+1
存储结构
顺序存储
可以使用一维数组存储二叉树的结点
完全二叉树

| 数组 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| a | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
可以利用完全二叉树的性质:对于结点i,如果存在左孩子,则左孩子的编号为2i,如果存在右孩子,则右孩子的编号为2i+1
a[0]可以直接弃掉,也可以存储结点的个数
非完全二叉树
非完全二叉树也可以用数组来表示,只不过需要把不存在的结点补成一棵完全二叉树

补成完全二叉树

| 数组 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| a | 7 | 1 | 2 | 3 | 4 | 0 | 5 | 0 |
将不存在的点用0表示
显然顺序存储方式会浪费掉许多空间,所以顺序存储比较适用于完全二叉树
链式存储
用链表存储二叉树,二叉树中每个结点用链表的一个链结点存储
二叉树最多有两个孩子结点,所以需要两个指针域
####结构原型
typedef struct
{
int data;
struct tree *leftChild,*rightChild;
}tree;
含有n个结点的二叉链表中,有n+1个空链域
遍历二叉树
二叉树可以看做是一个递归,因此可以使用递归的方法进行遍历

二叉树分为三个区域,根据根的访问方法分为先序遍历、中序遍历、后序遍历,无论使用什么顺序进行访问根,都是先访问左子树后访问右子树

递归遍历
先序遍历
先访问根,再依次访问左子树和右子树,时间复杂度为O(n)
遍历方法
若二叉树非空
- 先访问根结点
- 先序遍历左子树
- 先序遍历右子树
void preOrder(tree *t)
{
if(t==NULL)
return;
visit(t);
preOrder(t->lChild);
preOrder(t->rChild);
}
上图的遍历顺序为1->2->4->5->3->6
中序遍历
先访问左子树,再访问根,最后访问右子树,时间复杂度为O(n)
若二叉树非空
- 中序遍历左子树
- 访问根结点
- 中序遍历右子树
void inOrder(tree *t)
{
if(t==NULL)
return;
inOrder(t->lChild);
visit(t);
inOrder(t->rChild);
}
上图的遍历顺序为4->2->5->1->6->3
###后序遍历
先访问左子树,再访问右子树,最后访问根
若二叉树非空
- 后序遍历左子树
- 后序遍历右子树
- 访问根结点
postOrder(tree *t)
{
if(t==NULL)
return;
postOrder(t->lChild);
postOorder(t->rChild);
visit(t);
}
上图的遍历顺序为4->5->2->6->3->1
非递归遍历
借助栈
中序遍历
方法
- 依次扫描根结点左侧的所有结点,并将其一一进栈
- 出栈一个结点并访问
- 找到其右孩子结点并进栈
- 扫描右孩子的左侧结点并一一进栈
- 反复该过程,直到栈为空
void inOrder2(tree *t)
{
tree *p=t;
while(p||!isEmpty(t))
{
if(p)
{
push(p,t);
p=p->lChild;
}
else
{
pop(p,s);
visit(p);
p=p->rChild;
}
}
}
前序
- 依次访问左侧所有结点并进栈
- 出栈一个节点
- 访问它的右结点将其入栈
- 访问它的所有左节点并入栈
- 依次执行,直到为空
void preOrder(tree *t)
{
tree *p=t;
while(p||!isEmpty(t))
{
if(p)
{
push(p,s);
visit(p);
p=p->lChild;
}
else
{
pop(p,s);
p=p->rChild;
}
}
}
层次遍历
从上至下,从左到右进行遍历
使用队列
若二叉树非空
- 将根节点入队,出队并访问
- 若有左子树,则让左子树的根入队
- 若有右子树,则让右子树的根入队
- 入队完成后,出队,并依次访问
- 重复步骤,知到队为空
void bfs(tree *t)
{
queue *q;//初始化新的队列
tree *p;
enQueue(q,p);//头结点先入队
while(!empty(q))
{
dequeue(q,p);
visit(p);
if(p->lChild)
enqueue(q,p->lChild);
if(p->rChild)
enqueue(q,p->rChild);
}
}
总结
#include <stdio.h>
#include <stdlib.h>
typedef char ElementType;
typedef struct TNode *Position;
typedef Position BinTree;
struct TNode
{
ElementType Data;
BinTree Left;
BinTree Right;
};
BinTree CreatBinTree(); /* 实现细节忽略 */
void InorderTraversal(BinTree BT);
void PreorderTraversal(BinTree BT);
void PostorderTraversal(BinTree BT);
void LevelorderTraversal(BinTree BT);
void create(BinTree *t)
{
char ch;
scanf("%c", &ch);
if (ch == '#')
*t = NULL;
else
{
(*t) = malloc(sizeof(BinTree));
(*t)->Data = ch;
create(&(*t)->Left);
create(&(*t)->Right);
}
}
int main()
{
BinTree BT = CreatBinTree();
printf("Inorder:");
InorderTraversal(BT);
printf("\n");
printf("Preorder:");
PreorderTraversal(BT);
printf("\n");
printf("Postorder:");
PostorderTraversal(BT);
printf("\n");
printf("Levelorder:");
LevelorderTraversal(BT);
printf("\n");
return 0;
}
/* 你的代码将被嵌在这里 */
BinTree CreatBinTree()
{
BinTree t;
create(&t);
return t;
}
void InorderTraversal(BinTree BT)//中
{
if (BT == NULL)
{
return;
}
InorderTraversal(BT->Left);
printf(" %c", BT->Data);
InorderTraversal(BT->Right);
}
void PreorderTraversal(BinTree BT)
{
if (BT == NULL)
return;
printf(" %c", BT->Data);
PreorderTraversal(BT->Left);
PreorderTraversal(BT->Right);
}//先序
void PostorderTraversal(BinTree BT)
{
if (BT == NULL)
return;
PostorderTraversal(BT->Left);
PostorderTraversal(BT->Right);
printf(" %c", BT->Data);
}//后序
//BinTree为struct *类型
void LevelorderTraversal(BinTree BT)
{
if(BT==NULL)
return;
BinTree date[1000];
int rear, front;
rear = front = 0;
date[rear++] = BT;
BinTree t1, t2;
t1=date[front]->Left;
t2=date[front]->Right;
while (rear!=front)
{
t1=date[front]->Left;
t2=date[front]->Right;
printf(" %c",date[front]->Data);
front++;
if(t1)
date[rear++] = t1;
if(t2)
date[rear++] = t2;
}
}
由遍历序列构造二叉树(推导遍历结果)
- 已知先序遍历序列和中序遍历序列可以确定一颗二叉树
- 已知中序遍历序列和后序遍历序列可以确定一棵二叉树
- 已知先序遍历序列和后序遍历序列,无法确定一棵二叉树
方法
先序和中序
- 先序遍历序列中,第一个结点是根结点
- 根节点可将中序遍历序列分为两部分
- 再确定两部分的结点,两部分中先序序列出现的第一个结点分别是左子树和右子树的根
- 重复该过程,便能确定一棵二叉树
/*
* @Created by : SongXiaoxu
* @Copyright © 2021年 by: 宋晓旭. All rights reserved
* @Date: 2021-02-09 12:18:47
* @LastEditTime: 2021-05-21 16:45:38
*/
#include <bits/stdc++.h>
using namespace std;
typedef struct tree
{
int data;
struct tree *l, *r;
} tree;
const int N = 100;
int n, center[N], front[N];
void create(tree **t, int stc, int enc, int stf, int enf)
{
if (stc > enc || stf > enf)
return;
(*t) = (tree *)malloc(sizeof(tree));
(*t)->data = front[stf];
(*t)->l = (*t)->r = NULL;
int pos = 0;
while (center[pos] != (*t)->data)
pos++;
int len = pos - stc;
create(&(*t)->l, stc, pos - 1, stf + 1, stf + len);
create(&(*t)->r, pos + 1, enc, stf + len + 1, enf);
}
void print(tree *t)
{
if (t == NULL)
return;
print(t->l);
print(t->r);
printf("%d", t->data);
}
int main()
{
tree *tt = NULL;
cout<<"序列长度:"<<endl;
cin >> n;
cout<<"请输入中序遍历序列(数字之间用空格隔开):"<<endl;
for (int i = 0; i < n; i++)
cin >> center[i];
cout<<"请输入先序遍历序列(数字之间用空格隔开):"<<endl;
for (int i = 0; i < n; i++)
cin >> front[i];
create(&tt, 0, n - 1, 0, n - 1);
cout<<"后序遍历序列为:";
print(tt);
return 0;
}
后序和中序
- 后序遍历序列中,最后一个结点是根结点
- 根结点可以将中序遍历序列分为两部分
- 再根据两部分的结点,两部分中,后序序列倒数出现的第二个结点为右子树的根节点,以此类推
- 重复该过程,便能确定一棵二叉树
/*
* @Created by : SongXiaoxu
* @Copyright © 2021年 by: 宋晓旭. All rights reserved
* @Date: 2021-02-09 12:18:47
* @LastEditTime: 2021-05-21 17:15:21
*/
#include <bits/stdc++.h>
using namespace std;
typedef struct tree
{
int data;
struct tree *l, *r;
} tree;
const int N = 100;
int n, center[N], tail[N];
void print(tree *t)
{
if (t == NULL)
return;
print(t->l);
printf("%d", t->data);
print(t->r);
}
void create(tree **t, int stc, int enc, int stt, int ent)
{
if (stc > enc || stt > ent)
return;
(*t) = (tree *)malloc(sizeof(tree));
(*t)->data = tail[ent];
(*t)->l = (*t)->r = NULL;
int pos = 0;
while (center[pos] != (*t)->data)
pos++;
int len = pos - stc;
create(&(*t)->l, stc, pos - 1, stt, stt + len - 1);
create(&(*t)->r, pos + 1, enc, stt + len, ent - 1);
}
vector<int> a;
void bfs(tree *t)
{
queue<tree *> q;
q.push(t);
while (!q.empty())
{
tree *now = q.front();
q.pop();
a.push_back(now->data);
if (now->l)
q.push(now->l);
if (now->r)
q.push(now->r);
}
}
int main()
{
tree *tt = NULL;
cin >> n;
for (int i = 0; i < n; i++)
cin >>
tail[i];
for (int i = 0; i < n; i++)
cin >>
center[i];
create(&tt, 0, n - 1, 0, n - 1);
// print(tt);
bfs(tt);
for(int i=0;i<a.size();i++)
{
if(i==0)
cout<<a[i];
else
cout<<" "<<a[i];
}
return 0;
}
创建二叉树
方法1
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
char ch;
struct tree *lchild, *rchild;
} tree;
tree *create()
{
char ch;
scanf("%c", &ch);
if (ch == '#')
return NULL;
tree *t = malloc(sizeof(tree));
t->ch = ch;
t->lchild = create();
t->rchild = create();
return t;
}
void print(tree *t)
{
if (t == NULL)
return;
printf(" %c ", t->ch);
print(t->lchild);
print(t->rchild);
}
int main()
{
tree *t = create();
print(t);
return 0;
}
方法2
void create(BinTree *t)//BinTree为struct *类型
{
char ch;
scanf("%c", &ch);
if (ch == '#')
*t = NULL;
else
{
(*t) = malloc(sizeof(BinTree));
(*t)->Data = ch;
create(&(*t)->Left);
create(&(*t)->Right);
}
}
/*
* @Created by : SongXiaoxu
* @Copyright © 2021年 by: 宋晓旭. All rights reserved
* @Date: 2021-02-09 12:18:47
* @LastEditTime: 2021-02-13 17:56:07
*/
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
char value;
struct tree *l, *r;
} tree;
void create(tree **t)
{
char ch;
scanf("%c", &ch);
if (ch == '#')
{
*t = NULL;
} else
{
(*t) = (tree *) (malloc(sizeof(tree)));
(*t)->value = ch;
create((tree **) &(*t)->l);
create((tree **) &(*t)->r);
}
}
void print(tree *t)
{
if (t == NULL)
return;
printf("%c", t->value);
print((tree *) (t->l));
print((tree *) (t->r));
}
int main()
{
tree *t = NULL;
create((tree **) (&t));
print(t);
return 0;
}
两者除函数返回值不同之外,其他地方都相同
线索二叉树
为了解决浪费的n+1个空指针的问题
线索化
若无左子树,左指针指向它的前驱结点
若无右子树,右指针指向它的后继节点
前驱结点不是它的双亲节点!!!
先序线索二叉树
结构原型
与普通二叉树不同,需要额外的两个变量用来标记左右指针的作用,0为指向孩子结点,1为指向前驱结点或者后继节点
typedef enum{link,theread} flag;
typedef struct
{
elementType data;
flag lTag,rTag;
struct tree *lChild,*rChild;
}tree;
以上称为线索链表

中序线索二叉树是最常用的
中序线索二叉树遍历寻找前驱和后继结点的方法
#include<stdio.h>
#include <stdlib.h>
typedef enum
{
link, theHead
} flag;
typedef struct
{
char ch;
struct tree *lChild, *rChild;
int ltag, rtag;
} tree;
void create(tree **t)
{
char ch;
scanf("%c", &ch);
getchar();
if (ch == '#')
*t = NULL;
else
{
(*t) = malloc(sizeof(tree));
(*t)->ch = ch;
create(&(*t)->lChild);
create(&(*t)->rChild);
}
}
void preOrder(tree *t)
{
if (t == NULL)
return;
printf(" %c ", t->ch);
if (t->ltag != 1)
preOrder(t->lChild);
if (t->rtag != 1)
preOrder(t->rChild);
}
void inorder(tree *t)
{
if (t == NULL)
return;
inorder(t->lChild);
printf(" %c ", t->ch);
inorder(t->rChild);
}
tree *pre = NULL;
void inThread(tree **t)
{
if (*t == NULL)
return;
inThread(&((*t)->lChild));
if ((*t)->lChild == NULL)
{
(*t)->lChild = pre;
(*t)->ltag = 1;
}
if (pre != NULL && pre->rChild == NULL)
{
pre->rChild = *t;
pre->rtag = 1;
}
pre = *t;
inThread(&((*t)->rChild));
}
int main()
{
tree *t;
create(&t);
inThread(&t);
preOrder(t);
// puts("");
// inorder(t);
return 0;
}
因为线索化之后会有两个结点没有前驱/后继结点,因此有两个空指针,此时可以增设一个头节点,头节点的左孩子指向根节点,右孩子指向遍历序列的最后一个结点。再将两个空指针指向头节结点,最后构成一个循环链表。
Q.E.D.

