



集合
- 集合可以看作是一个容器
- 跟数组一样,都是对多个数据进行操作的
- 不涉及到硬盘的存储,仅针对于内存
数组的特点
- 一旦初始化,长度就确定了
- 一旦定义好,元素类型就确定了
- 缺点:初始化后,长度确定,无法修改长度
- 删除、插入数据效率低
- 缺点:初始化后,长度确定,无法修改长度
集合可以分为基于Collection接口和Map接口
都在java.util.包下
Collection,中文收藏、搜集、采集,读音kəˈlekSH(ə)n,单列数据
Map(映射),双列数据(键值对)
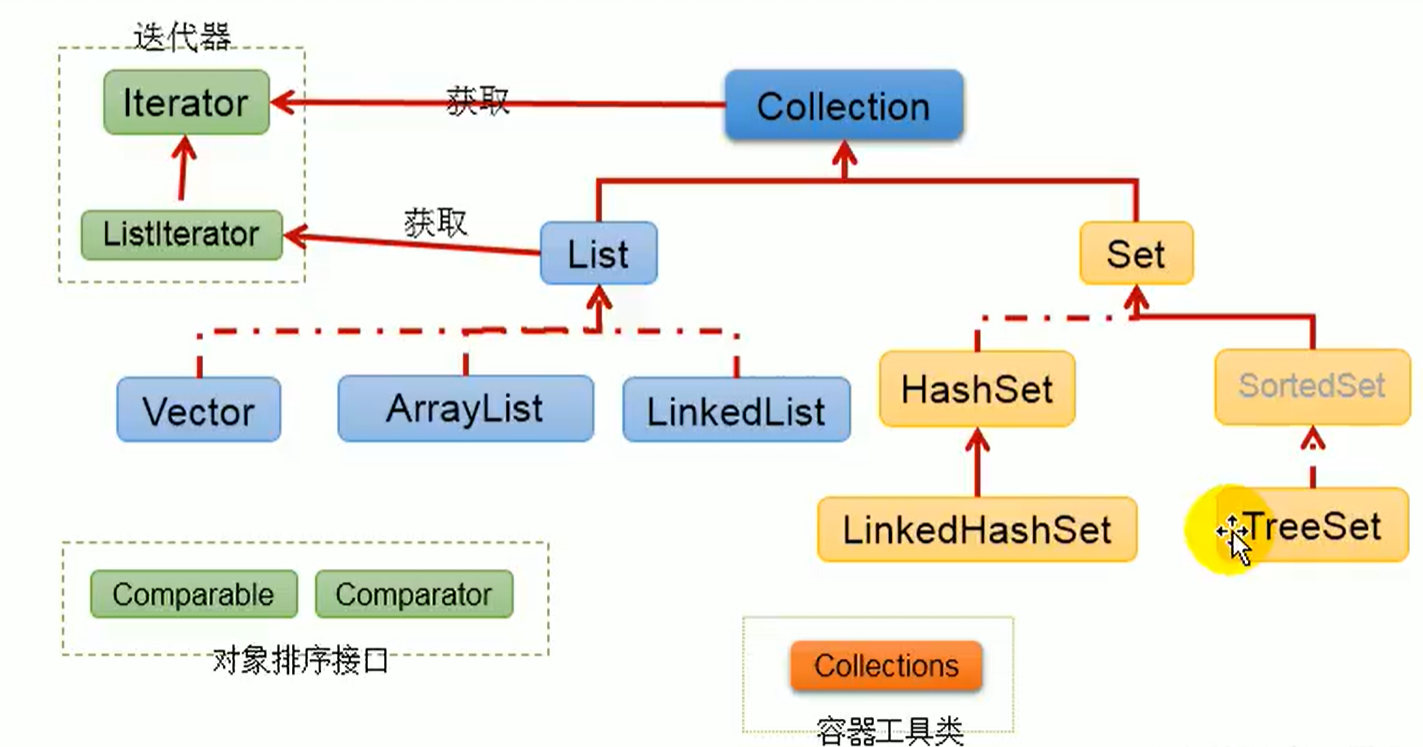
Collection接口
中文为收藏
分为List接口和Set接口
| 方法 | 含义 |
|---|---|
o.add(任意类型的值) | 添加元素,默认为Object类型 |
o.size() | 返回大小 |
o.addAll(开始位置, 一个对象) | 将一个对象从开始位置(从0开始)到最后的所有元素放到o中,如果省略开始位置参数,则将一个同接口的一个对象的所有元素添加进去 |
o.isEmpty() | 判断是否为空,布尔类型 |
o.clear() | 清空元素,clear中文为清除 |
o.contains(对象) | 查看o中是否存在对象,并不是使用==判断地址的,使用equals()方法进行判断,所以要想最好的实现效果,最好重写对象的equal()方法 |
o.containsAll(对象) | 查看被传入的对象中的元素是否都在o中 |
o.remove(对象) | 删除第一个与该值匹配的元素,也是通过equals()方法进行判断的值是否相等,返回布尔类型,用于查看是否移除成功 |
o.removeAll(对象) | 在o中删除对象中且o中也包含的所有元素 |
o.retainAll(对象) | 将o和对象的交集给o,retain 中文 保持、保留、拥有 |
o.equals(对象) | 判断两个集合是否相等,两个对象中的所有的值的都一样、顺序都一样,才会返回true |
o.hashCode() | 返回哈希值 |
o.toArray() | 返回Object[]类型 |
o.iterator() | 返回Iterator类型的接口,中文为迭代器,用于迭代器的遍历 |
Iterator接口
位于java.util.下
如果越界,会抛出异常
| 方法 | 含义 |
|---|---|
.hasNext() | 是否还有下一个元素 |
.next() | 将指针下移,并返回下移以后的值(Object类型) |
.remove() | 移除迭代器中上一个元素(在原来的集合中也跟着移除),如果调用过一次remove()方法,紧接着再次调用remove()方法时,会抛出异常 |
ArrayList b = new ArrayList();
b.add(1);
b.add(2);
b.add(3);
b.add(4);
b.add(4);
b.add(4);
Iterator iterator = b.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
增强for循环
JDK5.0新增
for(类型 变量 : 数组/集合){
//语句
}
增强for循环的循环体内不能直接给变量赋值,因为是将一个集合/数组的值赋给局部变量的,只相当于给局部变量赋值,因此不会影响到数组/集合的
List接口
存储有序的、可重复的数据,通常称为动态数组
实现类有ArrayList、LinkedList、Vector
三者的异同:
-
相同点:都是实现了
List接口,存储特点相同 -
不同点:
ArrayList是主要实现类,线程不安全的,执行效率高,底层采用Object[]存储Vector是一个古老的实现类,最早实现的一个类,线程安全,执行效率比较低,底层采用Object[]存储LinkedList使用双向链表进行存储,如果经常进行插入和删除,效率要比ArrayList要高
ArrayList类
JDK7以及之前
底层使用数组实现,空参构造时底层的数组默认大小为10,如果添加数据时,数组长度不够了,则默认扩容为原来的1.5倍,底层数组最大长度为int的最大值
为了提高效率,尽量使用带参的构造器,即new ArrayList(指定大小),指定里边的数组的大小
JDK8及以后
空参构造时,不会默认指定数组的大小,默认数组为null,只有在第一次添加数据时,才会给分配空间,默认分配10个数组大小,其他方面与JDK7相同
LinkedList类
中文为链表,使用双向链表进行存储
有一个内部类Node,每次插入一个元素相当于new一个内部类,使用尾插法进行插入的
Vector类
使用空参构造时,数组指定的大小默认也是10,添加数据扩容的长度是两倍
Collection中定义的接口在List中一样使用
在Arrays类中,有一个静态方法可以转换为List接口类型
-
Arrays.asList(数组/连续的值)返回一个List接口类型的对象-
int[] a = {22, 33, 44}; List l = Arrays.asList(a); //也可以不限制参数 List l = Arrays.asList(22, 33, 44);
-
| List常用方法 | 含义 |
|---|---|
o.add(插入位置, 对象/值) | 插入到指定位置,指定的位置的值从0到现在的长度 |
o.indexOf(对象) | 返回对象在o中的首次出现的下标,如果没有找到,返回-1 |
o.lastIndexOf(对象) | 返回对象在o中的最后出现的下标,如果没有找到,返回-1 |
o.remove(下标) | 删除下标处的值,是按照索引进行删除的,而不是Collection接口中的remove(对象)的方式删除的 |
o.set(指定位置, 对象/值) | 设置指定位置的值 |
o.subList(开始位置, 结束位置) | 返回Object[]类型,返回开始位置到结束位置之间的值 |
o.get(下标) | 返回Object类型,即下标处的值,如果不存在的下标,抛出异常 |
Set接口
底层相当于new HashMap()
是Collection接口的子接口,该接口中没有定义额外的方法,因此,相等于使用Collection接口中的方法
存储无序的、不可重复的数据,单纯的集合
不可重复性取决于equals()方法和hashCode()方法
如果hashCode()方法不重写,默认是随机指定的一个地址,所以需要重写
- 需保证添加数据时,
equals()方法不能返回true,即相同的元素不能够添加进来 - 仅通过
equals()方法进行比较,效率是低下的,可以先通过hashCode()方法计算散列地址,仅当散列地址相同时再调用equals()
HashSet类
Set接口的主实现类,线程不安全,可以存储null值,遍历时,并不是根据插入的顺序进行遍历,在其内部有一个顺序,是按照hashCode()方法给出的哈希值进行排序
底层调用的是HashMap类
底层也是使用数组进行存储,JDK7及以前默认的数组长度为16
散列值(哈希值)相同时,通过equals()方法进行对比查看值是否相等,再以此决定数据是否要放入,使用拉链法(链地址法)进行解决冲突

插入数据过程
向hashSet类中插入过程如下:
- 调用
.hashCode()方法,计算出要插入数据的哈希值- 如果与任意一个元素的哈希值不匹配,那么直接插入
- 如果匹配
- 计算出的哈希值所在位置有元素,再调用
equals()方法进行判断是否相等,如果相等就不插入,不相等就插入(JDK7以及之前采用头插法,JDK8及以后采用尾插法)
- 计算出的哈希值所在位置有元素,再调用
LinkedHashSet类
是HashSet的一个子类,进行遍历时,可以按照添加的顺序遍历
增加了两个指针域(前驱后继)来记录添加的顺序,对于频繁的遍历操作要比HashSet高
TreeSet类
可以按照添加元素的指定属性进行排序,因此,只能添加同一类型的数据
一般重写过CompareTo()方法的都按照从小到大的顺序进行排序
空参构造
TreeSet 对象名 = new TreeSet();
要想实现自动排序,必须再这个类中实现Comparable接口中的CompareTo()方法
判断是否存在于集合的标准是按照重写的CompareTo方法进行比较,如果是此方法返回的是0就代表存在,底层采用红黑树进行存储
带参构造
TreeSet 对象名 = new TreeSet(实现Comparator接口的类实例化的对象/匿名类);
参数可以填写实现Comparator接口的类实例化的对象,或者匿名类
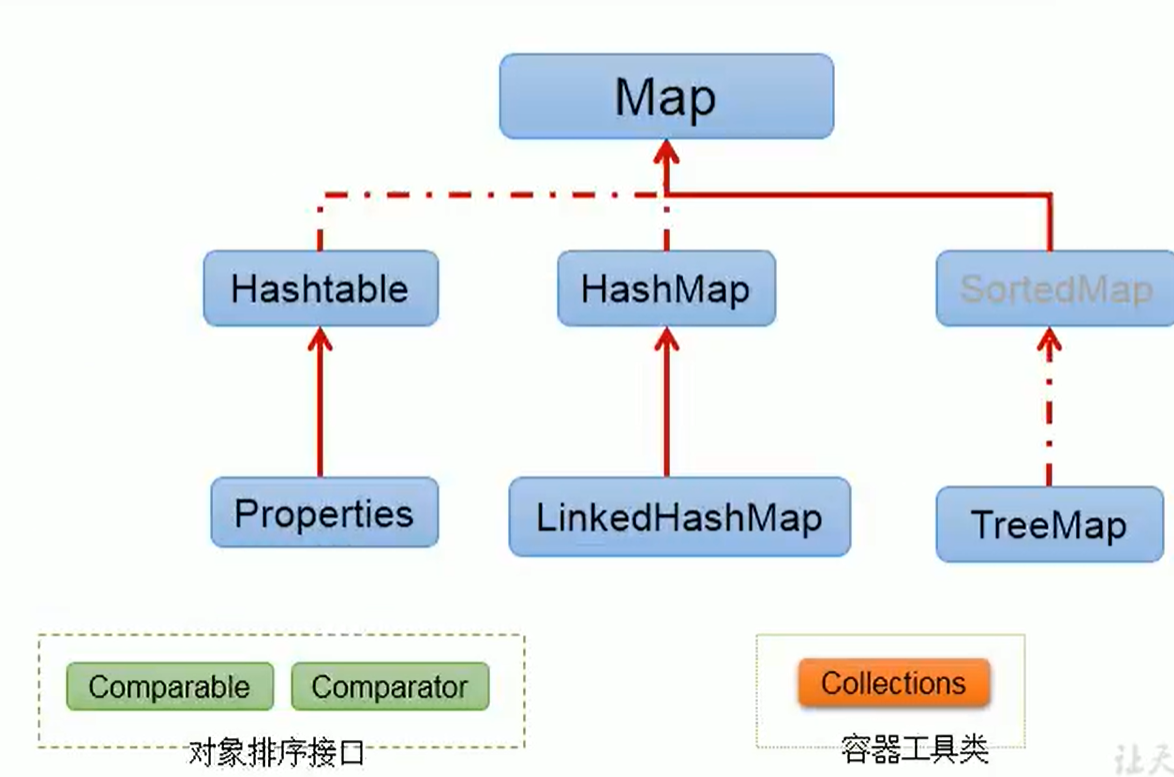
Map接口
键值对
key不能重复,无序- 需要重写
key对象的hashCode()方法和equals()方法
- 需要重写
value可重复,无序
| 方法 | 含义 |
|---|---|
o.put(key, value) | 添加数据 |
o.putAll(map对象) | 将另一个对象的值全部添加进去 |
o.remove(key) | 以key删除map中的一个键值对,返回一个Object类型,内容为value,如果要删除的key不存在,则返回null |
o.clear() | 清空map |
o.size() | 返回大小 |
o.get(key) | 返回Object类型,以key为键的value |
o.containsKey(key) | 返回Boolean类型,查看map中是否有对应的key |
o.containsValue(vaule) | 返回Boolean类型,查看map中是否有对应的value |
o.isEmpty() | 是否为空 |
o.equals(map) | 返回boolean类型,判断两个map是否相等 |
o.keySet()、o.entrySet() | 返回Set类型,将所有的key作为一个Set返回 |
o.values() | 返回Collection类型,将所有的value返回 |
HashMap类
Map接口的主要实现类,线程不安全,效率高
可以存储值为null的key和value
JDK7及之前使用数组和链表,JDK8及以后采用数组+链表+红黑树
底层实现原理
JDK7及之前:
-
实例化后,底层创建了一个大小为16的数组
-
添加数据后,先调用该数据的
hashCode()获取哈希值,计算位置- 查看位置上是否为空,也是使用链地址法,并且是头插法
- 如果不为空,并且插入的
key找到与已经存在的key相同,那么用新的value替换原有的value
-
扩容:默认的扩容方式为扩容到原来的2倍,并将数据复制进去
-
默认的加载因子为
0.75,临界值 = 容量 * 因子,当已用到的数组长度大于临界值时 数组会扩容,并不是等到用光后再扩容
JDK8及之后:
- 实例化时,没有创建数组
- 首次添加数据时,创建大小为16的数组
- 当数组的某一个索引位置元素以链表形式存在的个数大于8,数组长度大于64,此时改为红黑树进行存储
遍历map
不能直接使用迭代器进行遍历,可以调用.keySet()返回其key的集合,再用集合进行遍历
//集合辅助遍历
Set set = m.keySet();//调用.keySet()返回其key的集合
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object o = iterator.next();
System.out.println(o + " = " + m.get(o));
}
LinkedHashMap类
HashMap类的子类,遍历元素时,按照插入的顺序进行遍历,添加了指针指向前后元素,频繁的遍历时,效率比较高
SortMap接口
TreeMap类
实现了TreeMap接口,可以按照key进行排序,使用红黑树作为底层
key对象必须是同一类的对象,所以key需要实现Comparable接口或者使用Comparator接口的对象
Hashtable类
古老实现类,线程安全,效率低,无法存储值为null的key和value
properties类
Hashtable类的子类,处理配置文件,key和value都是String类型
中文为特性,读音praa·pr·teez
存数据:setProperty(String key, String value)
取数据:getProperty(String key),如果没有这个key,就返回null
Collections工具类
类似于Arrays类,内部大多都是静态方法
可以操作Collection接口(Set、List)、Map接口
| 方法 | 含义 |
|---|---|
Collections.reverse(List) | 翻转List |
Collections.shuffle(List) | 中文为洗牌,随机排列List中的元素ˈSHəfəl |
Collections.sort(List, Comparator) | 排序,需要实现Comparable接口时,Comparator可以省略。定制排序需要实现Comparator |
Collections.max/min(Collection接口对象, Comparator) | 求其中的最大值/最小值,Compatator可选,为定制排序的接口 |
Collections.frequency(Collection接口对象, 对象) | 返回对象在其中出现的次数,中文为频率,读音为frēkwənsē |
Collections.replaceAll(List, Object old, Object news) | 将List中的与old相等的对象替换成news对象 |
Collections.synchronizedList/Map/set | 默认情况下List/Map/set的线程是不安全的,使用此方法返回一个线程安全的 |
泛型
英文generic,中文为通用的,读音为jəˈnerik
可以看作是标签,JDK5.0新增特性
在定义类、接口时,添加一个标识,表明类中的某个属性或者某个方法的返回类型以及参数类型,泛型即参数化类型
集合中默认创建的对象可以添加任意形式的对象(此时作为Object对象接收),使用这种方法,如果要操作集合中数据时,需要类型转换
泛型的类型必须是类
集合中使用泛型
集合类型<对象类型> 变量名 = new 集合类型<对象类型>();
之后在此类型的对象中添加数据时,只能是指定的类型
迭代器也可以添加泛型
import java.util.*;
public class MapTest {
public static void main(String[] args) {
ArrayList<Integer> a = new ArrayList<Integer>();
a.add(1);
a.add(1);
a.add(1);
a.add(1);
a.add(1);
a.add(1);
a.add(1);
a.add(1);
a.add(1);
a.add(1);
a.add(1);
Iterator<Integer> iterator = a.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
在map中的指定Map类型<类型1, 类型2>变量名 = new Map类型<类型1, 类型2>()
自定义泛型结构
分为泛型类、泛型接口、泛型方法
如果定义了泛型类,如果实例化时不指明类型,默认为Object
在泛型中,不同的泛型不具备子父类关系
泛型类和泛型接口
-
如果一个类中某些类型不确定,可以使用泛型
-
类中的静态方法不允许用泛型,因为静态方法的加载要早于实例化对象
-
异常类也不能使用泛型
-
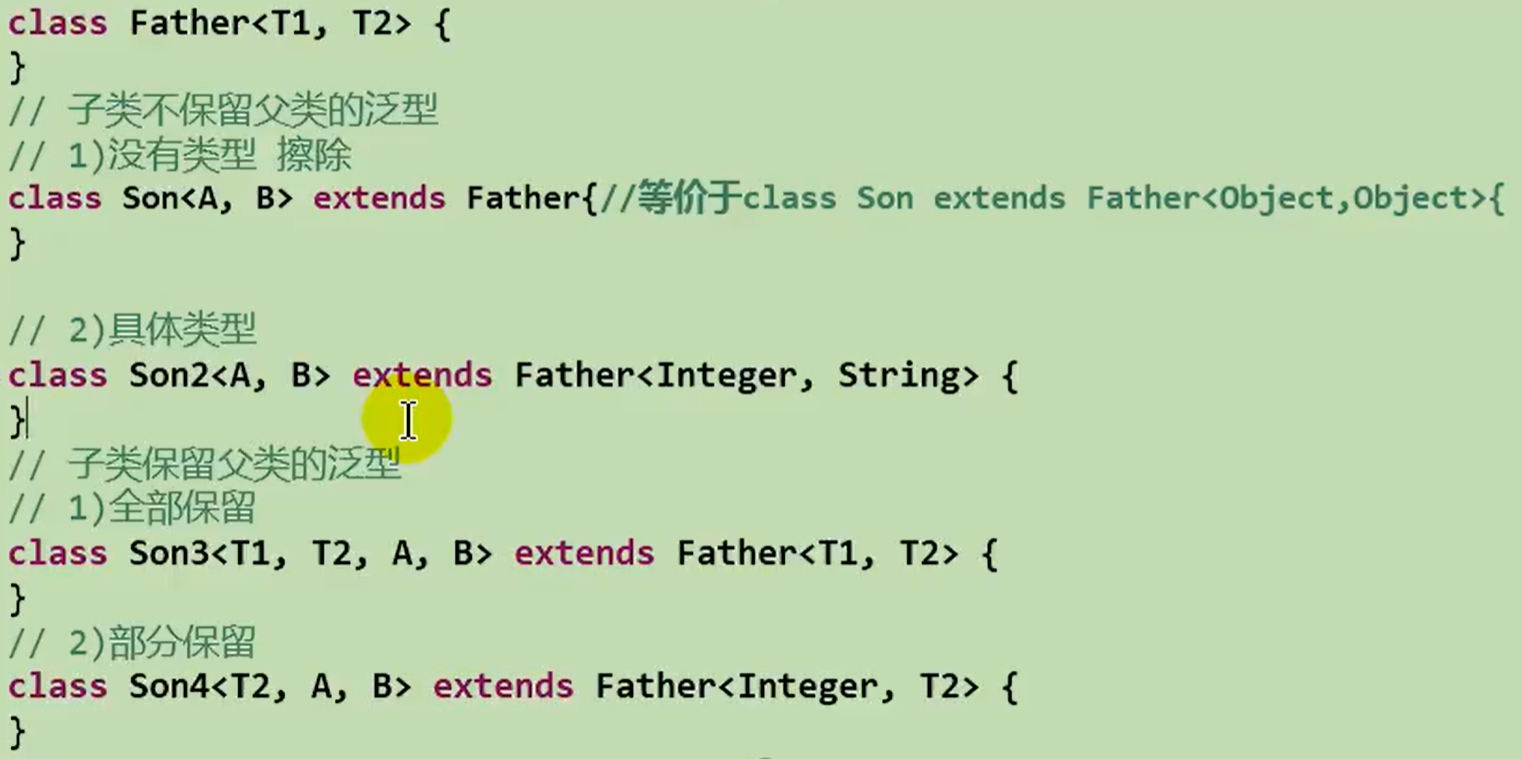
子类可以自由的选择保留父类中的泛型
-
不保留
-
class Father<T,P,Q>{ } class Son extends Father{ //此时Father的3个泛型都是Object } class Son2 extends Father<需要保留的 -

-
-
额外提供
-
class Father<T,P,Q>{ } class Son<A,B> extends Father{ //此时Father的3个泛型都是Object,自己又额外的增加了两个泛型 } //子类和父类中都保留时,按照标识的字母一一对应 -
-
-
格式
class 类名<类型的代表字符串1,...,n>{
}
//使用
类名<类型的代表字符串1,...,n> 变量名 = new 类名<类型的代表字符串1,...,n>(构造参数);
//JDK7及之后
类名<类型的代表字符串1,...,n> 变量名 = new 类名<>(构造参数);
之后可以使用这个字符串代表一个类型,有个不成文的规定:默认使用一个大写字母代表一个类型
泛型不同的两个对象之间不能相互赋值(即不能相互引用)
ArrayList<Integer> list = new ArrayList<>();
ArrayList<String> list2 = new ArrayList<>();
//不允许
list2 = list;
继承泛型类
//继承时指明泛型的类型
class 类1 extends 类2<已知的类型>{
}//指明后,类1就不是泛型了,因此实例化时无需再指明泛型的类型
//继承时不指明泛型的类型
class 类1<类型的代表字符串1,...,n> extends 类2<类型的代表字符串1,...,n>{
}

泛型变量
使用代表的字符串进行修饰变量类型
泛型方法
泛型方法并不是指返回值为已有泛型(该类是个泛型类)的方法
例如以下不是泛型方法
class Father<T>{//T时已有的泛型
public T fun(){
return new T;
}
}
泛型方法的格式
权限修饰符 <标识泛型的字符串> 含有标识泛型的字符串的返回值 方法名(泛型标识 参数名){
return 与泛型相关的参数;
}
以下是泛型方法
泛型方法可以是static,因为此时的泛型是调用时告知的类型
class Father<T>{
//不是泛型方法
public T fun(){
return new T;
}
//是泛型方法
public <E> E fun(E x) {
return x;
}
//以下也是泛型方法
public <F> ArrayList<F> fun2(F x,...,参数n){
return 与ArrayList<F>类相关的值;
}
}
通配符
?,可以看作两个不同泛型的父类
因为在泛型中,不同的泛型不具备子父类关系,例如
ArrayList<String> l = null;
ArrayList<Object> o = null;
l = o;
以上是不允许的
public static void printList(ArrayList<Object> o){
Iterator<Object> iterator = o.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
public static void main(String[] args) {
ArrayList<String> l = new ArrayList<>();
l.add("234");
l.add("234");
l.add("234");
l.add("234");
l.add("234");
//这也是不允许的,是两个独立的泛型
printList(l);
}
解决方案:使用通配符?
public static void printList(ArrayList<?> o) {
Iterator<?> iterator = o.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
public static void main(String[] args) {
ArrayList<String> l = new ArrayList<>();
l.add("234");
l.add("234");
l.add("234");
l.add("234");
l.add("234");
printList(l);
}
使用通配符之后,无法向被赋给通配符的引用中添加数据,但允许读取
public static void fun(ArrayList<?> o) {
o.add(合适类型的数据);//不允许
}
有限制条件的通配符
格式1<? extends 类>
限制传递进来的泛型只能是这个类或者是它的子类
格式2<? super 类>
限制传递进来泛型只能是这个类或者它的父类
Q.E.D.

