



基础内容
基本操作
-
登录命令
mysql -uroot -p密码 -
退出命令
exit -
显示所有数据库
show databases;
一定以分号结尾,默认带有4个数据库
-
使用某个数据库
use 数据库名; -
创建数据库
create database 名称; -
查看MySQL版本号
select version();只有见到分号才接着执行,如果强行停止,输入
\c,Ctrl + C也可以
表
数据库中最基本的单元是表,table
任何一张表都有行row,列column,中文:栏,柱子,发音kaa·luhm
行:被称为数据、记录,每行必须有一个不为null的数据
列:被称为字段,每个字段都是有字段名、约束、数据类型
查看数据库下有哪些表:
show tables;


导入表
source 路径;
路径不能有中文
查看表内容
select * from 表名;
中文是选择的意思,读音səˈlekt
*代表左右,from从,含义从这张表中查找所有
查看表的结构
desc 表名;
单表查询
查询一个字段名(列)
select 字段名 from 表名;
select和from是关键字
查询多个字段
使用逗号隔开
select 字段名1,...,字段名n from 表名;
查询所有字段:可以将所有的名称都写上,或者直接用*代替
使用*效率比较低,可读性差
显示别名
单个
select 字段名 as 别名 from 表名;
多个
在需要显示自己起的别名的字段名后加一个as 别名
select 字段名1 as 别名,...,字段名n as 别名 from 表名;
select不会做任何修改操作,只是显示
as关键字可以用空格代替
单个
select 字段名 别名 from 表名;
多个
在需要显示自己起的别名的字段名后加一个as 别名
select 字段名1 别名,...,字段名n 别名 from 表名;
如果别名中的有空格,可以使用单/双引号把整个别名给括起来,数据库中使用单引号作为标准,但MySQL可以用双引号
字段可以使用数学表达式(加减乘除运算):
select 字段名 数学表达式 from 表名;
-
例如:假设该表表名为tablex
-
+---------+| table1 |+---------+| 4 || 4 || 4 || 4 || 56 || 158 |+---------+ -
将字段table1的输出为*2后的值,可执行
-
select table1 * 2 from tablex;//也可以显示别名,y -
+--------+|table1*2|+--------+| 8 || 8 || 8 || 8 || 112 || 316 |+--------+
条件查询
不是将表中数据都查出来,只查符合条件的
语法格式:
select 字段1,...,字段nfrom 表名where 条件;
条件符号
=、!=相当于<>(大于小于)、>、<、>=、<=and,并且,优先级要比or高or或者in包含,在这几个值中- 语法
字段 in (值1, ..., 值n) - 例如
a = 2 or a = 4就相当于a in (2, 4)
- 语法
not非not in不包含,不在这几个值中,与in的含义相反is null,当某个值为null时,不能使用=null判断,只能使用is null,数据库中的null不是一个值,代表什么也没有,所以不能使用等号来衡量字段 between 值 and 值,必须遵循左小右大,闭区间,包含两端的值like称为模糊查询,支持%(代表匹配任意个字符)、_(下划线,代表只匹配一个字符)- 语法
字段 like ''- 例如查找
mail字段中以a开头的:mail like "a%"- 以a结尾的
mail like "%a" - 内容中含有a的
mail like '%a%'
- 以a结尾的
- 例如查找
- 语法
可以通过括号提升条件的优先级
排序
命令如下
select 字段名 from 表名order by 字段名1 desc,..., 字段名n;
默认为升序
可以按照多个字段排序
降序只需要在最后的字段名中加一个desc,即
select 字段名 from 表名order by 字段名1 desc,..., 字段名n;
如果强制指定升序,可以在最后的字段名中加一个asc
字段名可以用一个数字标识,这个数字代表第几列的字段
综合顺序
select ....from ....where ....order by ....
单行处理函数
函数可以用在条件查询where中
例如在abc表中查找name字段的开头字母为'a'的信息
select * from abc where substr(name, 1, 1) = "a";
一个输入对应一个输出,一行一行的处理
--例如对abc这个字段转为大写select upper(abc)from ....where ....order by ....
都是写在select之后
-
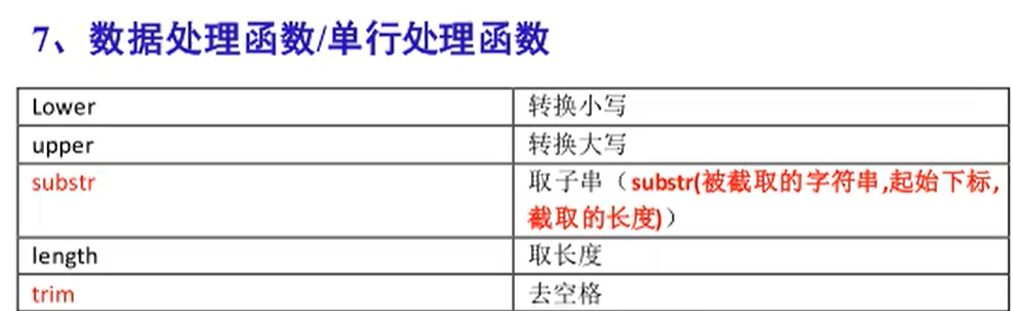
转换大小写(仅针对输出),
upper(字段名)大写,lower(字段名)小写 -
substr(字段名, 开始位置, 结束位置),取子串,起始下标从1开始 -
concat(字段1, 字段2),连接两个字符串,concat中文为连接 -
length(字段名),计算字段长度 -
trim(字段名),trim中文为修剪,取出前边的所有空格 -
round(字段名, 位数),中文为圆形、环,按照给定的位数进行四舍五入,如果位数是负数,则对相应的整数所在的位数进行四舍五入 -
rand()生成随机1以内的小数,可以配合round()得到特殊效果,比如100以内的随机数round(rand() * 100, 0) -
ifnull(字段名, 值),数据库中有null参与的运算都等于null,例如1 + null = null,如果字段名的值为空时,被当作参数2的值进行处理 -
case 字段 when 值1 then 表达式 when 值2 than 表达式........else 表达式 end当
字段的值=值1时然后表达式当字段的值=值2时然后表达式,否则 表达式--例如一个表ccc中有a b两个字段--现在有个条件,当a为1时,输出b为b*1.1--a为0时,b为b*1.2--其他情况b为b*1.5--输出这行所有内容select *, case a when 1 then b * 1.1 when 0 then b * 1.2 else b * 1.5 endfrom ccc; -
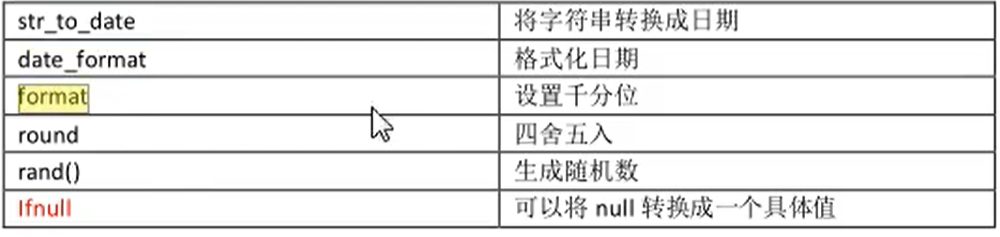
format,数字格式化,format(字段, "$999,999"),千分位格式化 -
str_to_date:将字符串varchar类型转换为date类型,str_to_date("日期字符串", "格式符 分隔符...")函数例如
str_to_date("2020-11-1", "%Y-%m-%d"),str_to_date("2020年11月1", "%Y年%m月%d") -
date_format:将date类型转换为具有一定格式的varchar类型,str_to_date(日期字段, "格式符 分隔符...")函数
多行处理函数(分组函数)
多个输入对应一个输出
使用前必须进行分组才能够被使用,如果没有分组,则整张表为一组
多个数据输出一个结果
sum(字段名)计算和count(字段名)计数,null不计入数量count(字段)计算该字段下不为null的元素个数count(*)计算表的总行数
max(字段名)求最大值min(字段名)求最小值avg(字段名)求平均值
用法select 函数 from 表名
因为有null参与的运算都等于null,但多行处理函数中,会忽略null
分组函数不能直接使用在where子句中
所有的分组函数可以一起用
select sum(字段名),count(字段名),max(字段名),min(字段名),avg(字段名) from 表名
分组查询
格式为
select...from...group by...
总的顺序,不可颠倒
select...from...where...group by字段order by...
执行顺序为:
- from
- where
- group by
- select
- order by
分组函数不能直接使用在where子句中的原因是where要早于group by执行
分组函数可以用在select之后的原因是group先于select执行,此时整张表作为的一组
例如
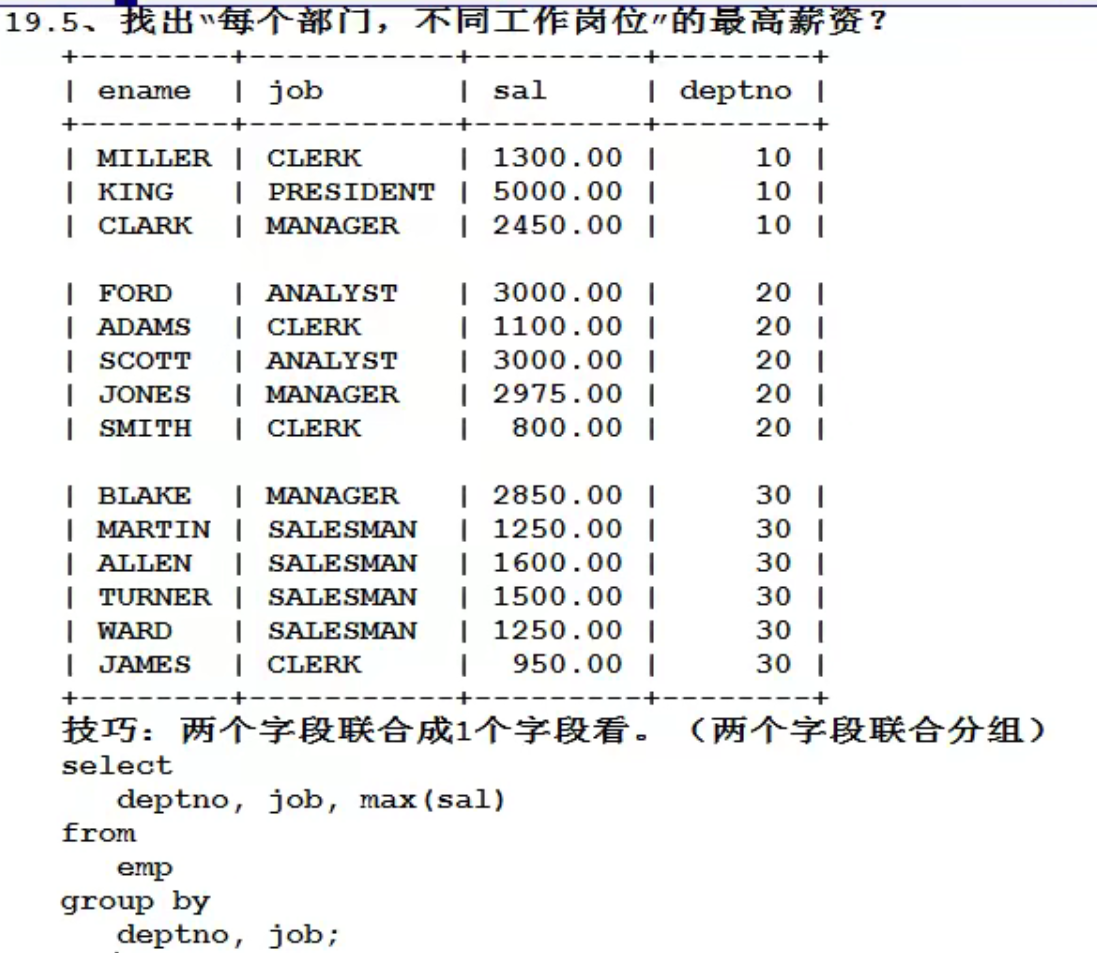
--表aaa+-----+-----+------+|name |class|price |+-----+-----+------+|苹果 |水果 |1 |+-----+-----+------+|芹菜 |蔬菜 |6 |+-----+-----+------+|香蕉 |水果 |3 |+-----+-----+------+|鸭梨 |水果 |4 |+-----+-----+------+|白菜 |蔬菜 |5 |+-----+-----+------+--分别计算蔬菜、水果的价格select class, sum(price) from aaa group by class;--即以字段class进行分组进行计算--也可以在select后添加其他属性,但没有意义--输出为+-----+----------+|class|sum(price)|+-----+----------+|水果 |8 |+-----+----------+|蔬菜 |11 |+-----+----------+
一般来说,select之后只能跟参加分组的字段、分组函数,添加其他的没有意义
也可以按照多个字段进行分组
-
select...from...group by 字段1, 字段2, ..., 字段n;-
含义为将整个按照字段1进行分组 -
在字段1的基础上,将每组按照字段2进行再次分组 -
以此类推,直到最后一个字段
-
结果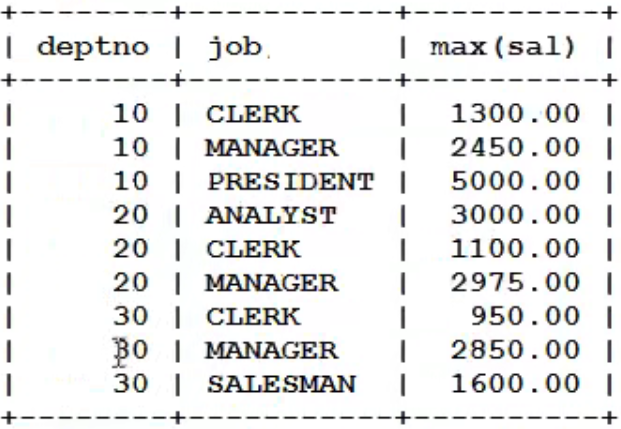
having语句
使用having语句可以对分完组之后的数据进一步过滤,having不能单独使用,必须跟着group by,不能代替by
select...from...where...group by字段having多行处理函数做的条件order by...
再比如以上求蔬菜和水果的价格的例子,再加一个只输出最后的价格大于10的种类,可以加一个条件
select class, sum(price) from aaa group by class having sum(price) > 10;+-----+----------+|class|sum(price)|+-----+----------+|蔬菜 |11 |+-----+----------+
如果having和where,所过滤的条件重合时,优先选择where
如果起了别名,可以在having中使用别名代替
distinct关键字
中文为独特的、明显、不同,读音为dəˈstiNG(k)t,目的是输出时去重
格式select distinct 字段名....,distinct只能出现在所有字段的最前端
如果有多个字段,那么distinct是将多个字段在一块联合起来去重,即相同的一行内容只出现一次
也可以和其他函数配合使用
多表查询
从一张表中的单独查询称为单表查询,从多张表中共同的取出数据进行查询称为多表查询
连接查询
根据语法分为:
- SQL92
- SQL99
根据连接方式分为:
- 内连接
- 外连接
- 左外连接(左连接)
- 右外连接(右连接)
- 全连接
如果两张表进行连接查询没有任何限制,会出现笛卡尔积的现象
表1+-----+| a |+-----+| aaa |+-----+| bbb |+-----+| ccc |+-----+表2+-----+| b |+-----+| ddd |+-----+| eee |+-----+| fff |+-----+执行select a, b from 表1, 表2;结果为+-----+-----+| a | b |+-----+-----+| aaa | ddd |+-----+-----+| aaa | eee |+-----+-----+| aaa | fff |+-----+-----+| bbb | ddd |+-----+-----+| bbb | eee |+-----+-----+| bbb | fff |+-----+-----+| ccc | ddd |+-----+-----+| ccc | eee |+-----+-----+| ccc | fff |+-----+-----+
可以通过添加条件来避免笛卡尔积现象
select ...from..,...,....where 表1.字段 条件 表2.字段.........
通过表名.字段可以避免不同表有相同的字段的情况,但没有减少匹配的次数
默认情况下,如果select后不指明该字段来自于哪张表,则会去from后的所有表中查找该字段,效率会比较低,可以通过添加表名.字段名进行指定在哪张表中查找,以此提高效率
也可以通过取别名的方式进行查询
例如
select e.a, p.bfrom egg e, pig p;where e.a = p.b;等价于select egg.a, pig.pfrom egg, pigwhere egg.a = pig.p
由笛卡尔积可得知,表的连接次数越多,效率越低,要尽量减少表的连接次数
内连接
分为自连接、等值连接、非等值连接
特点:能够匹配到数据进行查询,即每个记录都能够找到与之匹配的数据
等值连接
即在where或者on后的条件是判断是否相等的
SQL92的语法
select ...from..,...,....where 表1.字段 条件 表2.字段.........
SQL99的语法
select...from 表1 join(该处也可以写成inner join 但inner可以省略 中文为内,只起了增强可读性的作用,相当于,) 表2.....on....where...
SQL99中的on和where的作用一样
非等值连接
条件不是判等的连接
自连接
把一张表看成两张表,即一张表用两次,思路是给这个表取不同的别名
---表名为emp的表,保存着每个人的id、名字、领导的id,求每个人的领导,输出格式为自己的名字、领导的名字+------+--------+----------+| id | name | leaderID |+------+--------+----------+| 7369 | SMITH | 7902 || 7499 | ALLEN | 7698 || 7521 | WARD | 7698 || 7566 | JONES | 7839 || 7654 | MARTIN | 7698 || 7698 | BLAKE | 7839 || 7782 | CLARK | 7839 || 7788 | SCOTT | 7566 || 7839 | KING | NULL || 7844 | TURNER | 7698 || 7876 | ADAMS | 7788 || 7900 | JAMES | 7698 || 7902 | FORD | 7566 || 7934 | MILLER | 7782 |+------+--------+----------+把一张表看成两张表,即一张表用两次,思路是给这个表取不同的别名select a.name, b.name from emp a join emp b on a.leaderID = b.id;+--------+------------+| name | leaderName |+--------+------------+| SMITH | FORD || ALLEN | BLAKE || WARD | BLAKE || JONES | KING || MARTIN | BLAKE || BLAKE | KING || CLARK | KING || SCOTT | JONES || TURNER | BLAKE || ADAMS | SCOTT || JAMES | BLAKE || FORD | JONES || MILLER | CLARK |+--------+------------+KING的leader ID是null,所以表中没有,所以没有显示
外连接
特点:将内连接无法匹配到的数据进行查找出来
outer join,其中outer可以省略,中文为外
外连接查询出来的条数大于等于内连接查询出来的条数
右外连接
又被称为右连接
right:将join右侧的表看作是主表,目的是将右边表中的所有内容都查询出来,与左侧相关联,即产生了主次关系,内连接中两表没有主次关系
在join前进行修饰,即...right join...
表aaa+-----+-----+| a11 | a11 |+-----+-----+| 1 |第一行|| 2 |第二行|| 3 |第三行|+-----+-----+表bbb+-----+-----+| b | b22 |+-----+-----+| 1 |第一行|| 2 |第二行||null |第三行|+-----+-----+将aaa的a11字段和bbb的b字段进行相等的匹配,如果匹配 输出aaa的一整行select a.* from aaa join bbb on aaa.a11 = bbb.b;结果为+-----+-----+| a11 | a11 |+-----+-----+| 1 |第一行|| 2 |第二行|+-----+-----+此时是内连接,因为null不匹配,所以不显示右外连接select a.* from aaa right join bbb on aaa.a11 = bbb.b;+-----+-----+| a11 | a11 |+-----+-----+| 1 |第一行|| 2 |第二行||null |第一行||null |第二行||null |第三行|+-----+-----+
三张表及以上的连接
select....from a join b on a和b的连接条件 join c on a和c的连接条件 ....
内连接和外连接可以混合出现
子查询
select语句中嵌套select语句
可以出现在select后、from后、where后
where后的子查询
格式select...from...where 条件(select from....where.....)
from后的子查询
可以将子查询的结果当作一个临时表
格式
select...from(select 字段名 别名....) 别名...
from中的子表一定要有别名!
例子
表emp+-------+--------+-----------+------+------------+---------+---------+--------+| EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO |+-------+--------+-----------+------+------------+---------+---------+--------+| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.00 | NULL | 20 || 7499 | ALLEN | SALESMAN | 7698 | 1981-02-20 | 1600.00 | 300.00 | 30 || 7521 | WARD | SALESMAN | 7698 | 1981-02-22 | 1250.00 | 500.00 | 30 || 7566 | JONES | MANAGER | 7839 | 1981-04-02 | 2975.00 | NULL | 20 || 7654 | MARTIN | SALESMAN | 7698 | 1981-09-28 | 1250.00 | 1400.00 | 30 || 7698 | BLAKE | MANAGER | 7839 | 1981-05-01 | 2850.00 | NULL | 30 || 7782 | CLARK | MANAGER | 7839 | 1981-06-09 | 2450.00 | NULL | 10 || 7788 | SCOTT | ANALYST | 7566 | 1987-04-19 | 3000.00 | NULL | 20 || 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.00 | NULL | 10 || 7844 | TURNER | SALESMAN | 7698 | 1981-09-08 | 1500.00 | 0.00 | 30 || 7876 | ADAMS | CLERK | 7788 | 1987-05-23 | 1100.00 | NULL | 20 || 7900 | JAMES | CLERK | 7698 | 1981-12-03 | 950.00 | NULL | 30 || 7902 | FORD | ANALYST | 7566 | 1981-12-03 | 3000.00 | NULL | 20 || 7934 | MILLER | CLERK | 7782 | 1982-01-23 | 1300.00 | NULL | 10 |+-------+--------+-----------+------+------------+---------+---------+--------+表 salgrade+-------+-------+-------+| GRADE | LOSAL | HISAL |+-------+-------+-------+| 1 | 700 | 1200 || 2 | 1201 | 1400 || 3 | 1401 | 2000 || 4 | 2001 | 3000 || 5 | 3001 | 9999 |+-------+-------+-------+求表1的平均工资在表2中的等级select salgrade.GRADE from ( select avg (emp.SAL) anotherName1 from emp ) anotherName2 join salgrade on anotherName2.anotherName1 between salgrade.LOSAL and salgrade.HISAL; 表dept+--------+------------+----------+| DEPTNO | DNAME | LOC |+--------+------------+----------+| 10 | ACCOUNTING | NEW YORK || 20 | RESEARCH | DALLAS || 30 | SALES | CHICAGO || 40 | OPERATIONS | BOSTON |+--------+------------+----------+将表1,2,3结合起来,求每个部门的平均工资等级from (select emp.DEPTNO anotherName0, avg(emp.SAL) anotherName1 from emp group by emp.DEPTNO) anotherName2 join salgrade on anotherName2.anotherName1 between salgrade.LOSAL and salgrade.HISAL join dept on dept.DEPTNO = anotherName2.anotherName0;
select后的子查询
语法
select ....,(select....)........
比如
之前的表1和表2配合起来查员工的名字和所在部门,可以使用select emp.ENAME, dept.DNAME from emp join dept on emp.DEPTNO = dept.DEPTNO;也可以使用:select emp.ENAME, ( select dept.DNAME from dept where emp.DEPTNO = dept.DEPTNO) from emp;
对于select后的子查询语句要求只返回一条记录,如果返回一条以上会报错
union合并查询结果集
可以将多次查询到的结果拼接在一起
比如在表a中查询字段length = 1或者字段length = 2的所有记录
select * from a where length in (1,2);
也可以分开查询,使用union进行合并,使用这种方法的效率要比一起查询要高
select * from a where length = 1unionselect * from a where length = 2;
在连接表中效率比较高
假设一个表中a连接b,b连接c,a b c各有10条记录,如果用普通的方式进行连接,那么匹配次数为10*10*10,如果使用union,匹配次数为10*10 + 10*10=200
使用条件:
- 两个结果集的列数相同
MySQL允许不同数据类型列合并在一起,Oracle不允许
limit
通常将查询结果的一部分取出来,中文为限制
limit 数字表明取出记录的个数(下标从0开始),写在查询语句的最后
limit 数字1, 数字2,数字1为开始位置,数字2为取的个数,下标从0开始
例如limit 10, 7代表从下标10的位置往后取5条记录
在order by之后执行
若每页显示n条数据,则:
- 第
m页开始的范围是n * (m-1),使用limit可表示为:limit(n * (m - 1), n)
SQL语句书写顺序:
select...from...where...group by...having....order by...limit...
SQL语句执行顺序:
fromwheregroup byhavingselectorder bylimit
找到表->进行筛选条件->分组->对分好的组进行筛选条件->选择数据项->排序->取出部分数据
表的操作
增删改查
表的创建
create table 表名( 字段名1 数据类型(建议长度), ...., 字段名n 数据类型(建议长度));
表名和字段名都属于标识符
也可以在创建时指定默认值
create table 表名( 字段名1 数据类型(建议长度) default 值, ...., 字段名n 数据类型(建议长度));
| 类型 | 含义 |
|---|---|
varchar | 可变长度的字符串,可以根据传递的字符串的长度动态分配空间,比较节省空间,速度比较慢,最长存储255个字符 |
char | 定长字符串,不会动态分配空间,使用不当会导致空间浪费,速度比较快,最长存储255个字符 |
int | 整形,最长11位 |
bigint | 长整型 |
float | 单精度浮点型 |
double | 双精度浮点型 |
datetime | 长日期类型,包含年月日时分秒 |
date | 短日期类型,只包含年月日 |
clob | 字符大对象,最多可以存储4个G的字符串,超过255个字符的字符串要用该类型存储,全称为:Character Large Object,large中文为大的 |
blob | 存储二进制大对象,全称为:Binary Large Object,专门存储二进制文件,例如图片、声音等,需要使用IO流 |
快速创建表
表的快速复制,相当于备份
create table 新的表名 select * from 要被复制的表;或者create table 新的表名新的表名 as select * from 要被复制的表;‘
也可以用筛选出来的数据创建表
create table 新的表名 select 字段 from....where...;
删除表
-
drop table 表名;,drop中文为落下,是使用该方法进行删除时,如果表不存在会报错 -
drop table if exists 表名,exists中文为存在,如果表存在时才删除,不会报错
插入数据
insert into 表名(字段1, 需要插入数据的字段, 字段n) values(值1, ..., 值n);
字段名和值要一一对应,字段名的顺序可以随意,但值要对应
如果只指定了部分字段,那么其他字段为null
insert只要执行成功,就会多一条记录
也可以将字段名省略掉,相当于所有的字段名都写上,所以值也应该都写上
insert into 表名 values(所有的值都写上);
插入日期
MySQL日期格式:
%Y:年%m:月%d:日%h:时%i:分%s:秒
需要使用str_to_date("日期字符串", "格式符 分隔符...")函数
例如str_to_date("2020-11-1", "%Y-%m-%d"),str_to_date("2020年11月1", "%Y年%m月%d")
如果日期的格式满足 年-月-日的格式,无需使用str_to_date()函数进行转换
日期转varchar
date_format(date, "%m月%d日%Y年")11月01日2020年
默认短日期格式:%Y-%m-%d
默认长日期格式:%Y-%m-%d %h:%m:%s
当前时间:now()函数,带有时分秒
一次插入多条记录
insert into 表名(字段列表) values (数据列表1), ..., (数据列表n);
将筛选结果插入到一个表中
insert into 表名 select 字段 from....where...;
能够被插入的条件是筛选出来的表的结构符合当前表的结构
修改
使用update进行标识
语法update 表名 set 字段名1 = 值1, ..., 字段名n = 值n where 条件
没有条件限制会导致所有数据更新
例如
student表+------+--------+------+| id | name | age |+------+--------+------+| 0001 | admin | 33 || 0002 | guest | 33 || 0003 | system | 33 || 0004 | user | 33 |+------+--------+------+如果执行 update student set name = "test"; # 此时没有加where条件结果为+------+------+------+| id | name | age |+------+------+------+| 0001 | test | 33 || 0002 | test | 33 || 0003 | test | 33 || 0004 | test | 33 |+------+------+------+可见,将所有的name字段全部替换成test了可以使用where来区别要修改的字段,例如把admin的名字修改为testupdate student set name = "test" where name = "admin";+------+--------+------+| id | name | age |+------+--------+------+| 0001 | test | 33 || 0002 | guest | 33 || 0003 | system | 33 || 0004 | user | 33 |+------+--------+------+
删除一条记录
使用update进行标识
语法delete from 表名 where 条件
没有条件限制会导致所有数据都会被删除
快速删除数据
使用delete删除效率比较低,是将每个字段一行一行的挨个删除,空间不会被释放,优点是删除之后可以恢复,即不会在硬盘上删除
使用truncate语句,中文为截断,读音为ˈtrəNGˌkāt,是物理删除,效率比较高,但不支持回滚
语法truncate table 表名,是将整个表删除
表的结构增删改
让设计人员背锅
约束
英文为constraint,中文是约束,读音kənˈstrānt
在创建表时可以给表上的字段加一些约束条件,来保证数据的完整性、有效性,作用就是保证表中的数据有效
包括:
- 非空约束
- 唯一性约束
- 主键约束
- 外键约束
- 检查约束(
MySQL不支持,仅Oracle支持)
非空约束 not null
约束的字段不能为null
在创建时进行约束
create table student( id varchar(10) not null, name varchar(10), age int(3));
被约束为非空的字段上必须有值,不能为空
唯一性约束 unique
unique中文为唯一的、独特的,读音为yo͞oˈnēk
仅使用unique约束的字段不能够重复,但可以为null,如果和not null结合在一块可以表示为字段不能够重复且不能为null
如果有多个约束条件,可以加空格
create table student( id varchar(10) unique not null , #多个约束条件 name varchar(10) not null , age int(3));
表级约束
放到列后边的,需要给所有的字段添加某个约束时,比方说都不为空
可以解决两个字段联合起来具有唯一性,即两个完全相同的字段无法插入,两个不相同的字段可以插入
例如
一个表中具有id和name字段id = 1, name = "admin"id = 2, name = "admin"对于此种情况可以插入id = 1, name = "admin"id = 1, name = "admin"对于此种情况不可以插入
写法为:在创建时,另起一行,写unique(字段1, 字段2)
即
create table info( id int(5), email varchar(255), unique(id, email) #另起一行);
列级约束
直接为单个字段定义的约束,比如
name varchar(10) not null
主键约束 primary key
简称PK
在MySQL中,当not null和unique共同的放到某个字段后,代表该字段是逐渐约束
primary中文为 主、主要、最初、第一,读音为ˈprīˌmerē
术语:
- 主键约束
- 一种约束
- 主键字段
- 该字段上添加了主键约束
- 主键值
- 主键字段中的每一个值
- 是每一行记录的唯一标识,是每一行记录的身证份号
- 一般是定长的,不建议使用
varchar,一般使用int、char、bigint
任何一张表都应该有主键,没有主键,表无效,因为修改数据时可以使用主键进行区别每一行数据
主键的特征:not null + unique,即既不能为空,又必须是独特、唯一的
添加:
create table student( id varchar(10) primary key, name varchar(10), age int(3));
也可以使用表级约束,以上就相等于
create table student( id varchar(10), name varchar(10), age int(3), primary key(id));
一个字段做主键,称为单一主键
多个字段做主键,称为复合主键
单一主键最常用,一张表只能添加一个主键约束(联合起来添加的也算一个)
自然主键和业务主键
主键单纯的只是用来标识这一行的自然数,和业务无关,称为自然主键
跟其后的数据有关主键称为业务主键,例如银行卡号、身份证号
自然主键使用较多
主键可以使用auto_increment方式自增,increment 中文为增量,读音为ˈiNGkrəmənt
create table student( id varchar(10) primary key auto_increment, name varchar(10), age int(3));
其后无需再指定id的值,可以自动从1开始,逐条自动生成
外键约束 foreign key
foreign中文 外国的 国外 对外 外,读音为ˈfôrən,简称FK
某个字段的值只能是某几个(类似于性别只能选男/女)
语法:
foreign key(字段名) reference 表名(字段名2)
标识这个表中的该字段的值只能是来自于表名的字段名2
reference中文为参考,读音为ˈref(ə)rəns
学校表中存储着班级id和班级名info表中存储着每个人的id、姓名、班级号(只能来自于已有的班级id)create table school( classID int(5) unique primary key auto_increment, className varchar(5) unique);create table info( id int(5) unique primary key auto_increment, name varchar(255), classNum int(3), foreign key(classNum) references school(classID));insert into school(className) values("高一一班"),("高一二班"),("高一三班"),("高一四班");insert into info(name, classNum) values("大狗", 1);insert into info(name, classNum) values("r狗", 2);insert into info(name, classNum) values("s狗", 3);select * from info;select * from school;mysql> select * from info;+----+------+----------+| id | name | classNum |+----+------+----------+| 2 | 大狗 | 1 || 3 | r狗 | 2 || 4 | s狗 | 3 |+----+------+----------+3 rows in set (0.00 sec)mysql> select * from school;+---------+-----------+| classID | className |+---------+-----------+| 1 | 高一一班 || 3 | 高一三班 || 2 | 高一二班 || 4 | 高一四班 |+---------+-----------+4 rows in set (0.00 sec)mysql>
外键的值可以位null(前提不限制不能为空),使用外键引用外表的字段时,需要保证这个字段是唯一的(unique)不用保证必须是主键
存储引擎

显示存储引擎

事务 transaction
transaction 中文为交易、合同、合约,读音为tranˈzakSH(ə)n
一个完整的业务逻辑,例如a账户向b账户转账1万,a账户减少1万,b账户增加1万
只能同时成功或者同时失败
只有insert、update、delete和事务有关系,其他的都没有关系,一旦涉及到增删改就必须考虑安全问题,即DML语句同时成功或者失败
每个DML语句执行中都会记录到事务的日志文件
事务的执行过程中也可以提交事务和回滚事务
提交事务:
- 清空日志文件,将数据全部彻底的写入到数据库文件中
- 标志着事务的结束,并且是一种全部成功的结束
回滚事务:
- 将之前DML操作的全部撤销,并且清空日志文件
- 标志着事务的结束,是一种全部失败的结束
在mysql中,事务是自动提交的,即每执行一次DML语句就会自动给提交一次
可以关闭自动提交机制,即开启事务
start transaction;
提交事务
commit;,中文为犯罪、承诺、保证,读音为kəˈmit
回滚事务
rollback;,中文为回滚,读音为ˈrōlˌbak
只能回滚到上一次的提交点,也就是执行start transaction前的状态

事务的隔离性
隔离级别,从低到高依次为:
- 读未提交:
read uncommitted,没有提交也能读到- 事务a读到了事务b未提交的数据,存在脏读现象(dirty read),也就是读到了脏数据,这种隔离级别仅存在于理论上,大部分数据库都是最低从
读已提交开始
- 事务a读到了事务b未提交的数据,存在脏读现象(dirty read),也就是读到了脏数据,这种隔离级别仅存在于理论上,大部分数据库都是最低从
- 读已提交:
read committed,提交之后才能读到- 事务a只能读取到事务b已经提交的数据,解决了脏读现象,但有不可重复读取数据的问题
- 不可重复读取:第一次读取数据时,当前事务没有提交,当前事务结束后,再次读取时,与第一次读取到的不一样(假设第一次读取到的时3条,第二次可能是5条)
- 是比较真实的数据,每一次读取到的数据都绝对真实
- 这是
Oracle默认的隔离级别
- 事务a只能读取到事务b已经提交的数据,解决了脏读现象,但有不可重复读取数据的问题
- 可重复读:
repeatable read,提交之后也读不到- 每次读取到的数据都一样,无论是否提交了事务,即使数据发生了变化,也和第一次读取到的一样
- 解决了不可重复读的问题,但可能存在幻影读,每一次读取到的数据都是幻象,不够真实
- 这是
MySQL默认的隔离级别
- 序列化/串行化读:
serializable- 最高事务隔离级别,效率最低,解决了所有的问题,表示事务排队,不能并发
- 如果一个窗口(窗口1)正在操作这个表,则另一个窗口(窗口2)执行其他操作会暂停(光标闪烁),只有(窗口1)先操作的操作完之后,另一个窗口(窗口2)才会继续执行
查看事务隔离级别
MySQL8及之后的版本
mysql> select @@transaction_isolation;+-------------------------+| @@transaction_isolation |+-------------------------+| REPEATABLE-READ |+-------------------------+1 row in set (0.00 sec)
MySQL8之前
select @@tx_isolation
设置全局的事务隔离级别
set global transaction level 事务等级;
isolation,中文为隔离,读音为ˌīsəˈlāSH(ə)n
索引
是在数据库的字段上添加的,为了提高查询效率,可以缩小查找范围
如果没有加索引那就是全表扫描
索引也需要排序,MySQL中,索引是一棵B-树
在任何数据库中,主键都会自动添加索引,在MySQL中,如果一个字段使用unique进行约束,也会自动添加索引


需要添加索引的情况:
- 该字段经常被查询
- 数据量庞大
- 该字段有很少的DML操作,因为经过DML后,索引需要重新排序,即很少进行增删改
索引太多会降低系统的性能
创建索引
给一个表的某个字段添加索引
create index 索引名 on 表名(字段名);
删除索引
drop index 索引名 on 表名;
查看是否使用索引
在查询命令前添加explain例如explain select * from info where a = "aaa";在输出语句中,如果type为ALL,代表没有索引,如果为ref,代表有索引#没有索引,此时type为ALL+----+-------------+-------+------------+------+| id | select_type | table | partitions | type |+----+-------------+-------+------------+------+| 1 | SIMPLE | emp | NULL | ALL | +----+-------------+-------+------------+------+#有索引,此时type为ref+----+-------------+-------+------------+------+| id | select_type | table | partitions | type |+----+-------------+-------+------------+------+| 1 | SIMPLE | emp | NULL | ref | +----+-------------+-------+------------+------+
explain,中文为解释、说明,读音为ikˈsplān
索引的失效
-
如果一个字段加了索引,
where后使用like %会进行模糊查找,要挨个对比 -
or,如果where后使用了or,需要保证or两端都必须有索引才能够走索引,如果有一边没有,则另一端的索引会失效,可以考虑采用union方式 -
复合索引:
create index 索引名 on 表名(字段名1, ..., 字段名n);,如果没有使用左侧的字段名进行查找,也会导致索引失效 -
where中,索引参加了数学运算- 例如a字段走索引,而执行
select...from...where a + 1 = 9不走索引
- 例如a字段走索引,而执行
-
添加了单行处理函数
- 例如a字段走索引,而执行
select...from...where lower(a) = 'aaaa'不走索引
- 例如a字段走索引,而执行
视图 view
站在不同的角度看一份数据,可以对视图对象进行增删改查,但进行删改查会对原表进行修改
可以把视图看作是一个新表,但对这个新表进行操作会影响到原表,同样的,原表的数据修改也会影响到视图
创建
create view 视图名 as select ....
将某个条件筛选出来的数据给一个视图,只有查询语句才可以给一个视图
删除
drop view 视图名;
增删改查,简称CRUD
C:create,创建----增
R:retrieve,取回、恢复,读音为rəˈtrēv----查
U:update,更新----改
D:delete,删除----删
DBA命令
创建新用户
必须在root权限下
create user 用户名 identified 密码字符串;
identify中文为确认,读音为īˈden(t)əˌfī
查看文档
导出数据库
在终端中执行,而不是在登录后执行
mysqldump 数据库名 > 路径(尽量不要有中文)xxx.sql -u用户名 -p密码 #导出整个数据库mysqldump 数据库名 表名 > 路径(尽量不要有中文)xxx.sql -u用户名 -p密码 #导出一张表
例如
mysqldump testsql > C:\Users\singx\Desktop\file\1.sql -u用户名 -p密码
设计范式
按照范式进行设计表不会产生数据的冗余和空间的浪费
第一设计范式
所有的表都必须有主键,数据必须是不可再分的

这个表不符合第一范式,因为联系方式可以继续分

第二设计范式
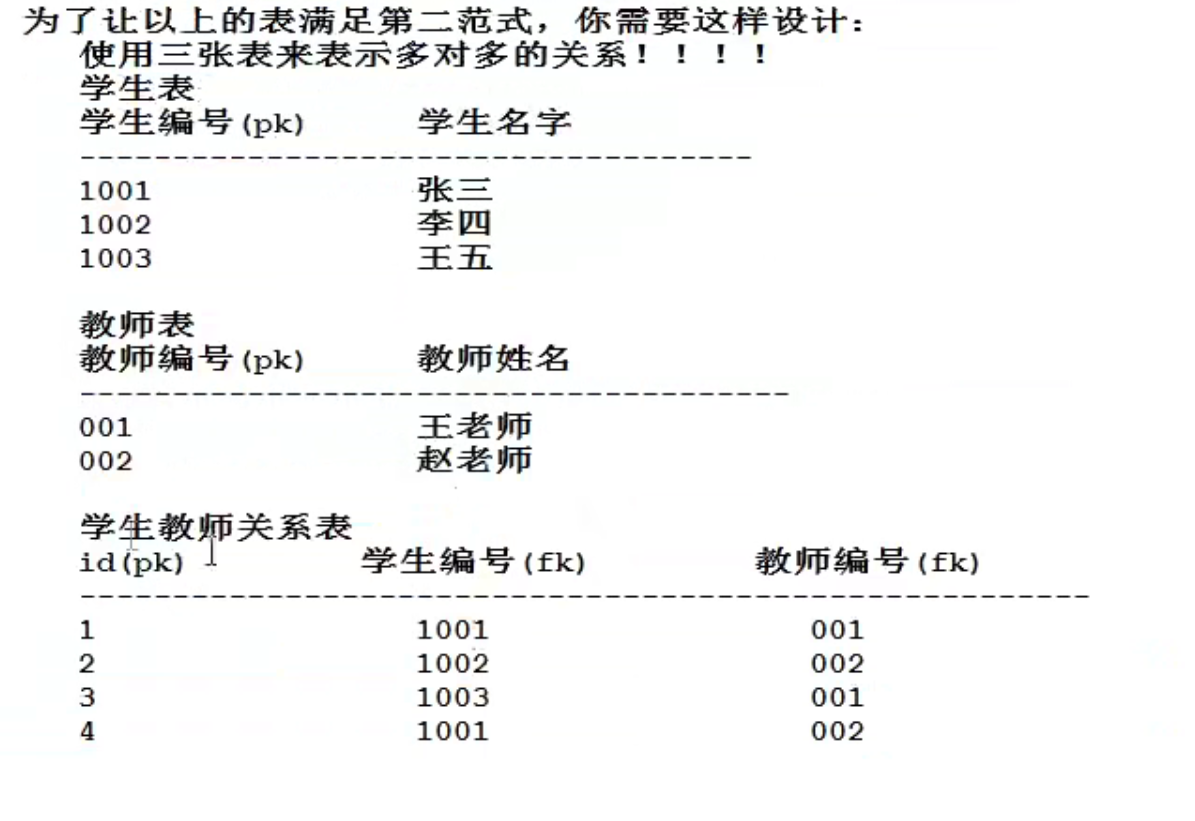
所有的非主键字段完全依赖于主键,不能部份依赖,建立在第一设计范式之上,满足多对多,多个表 可以设置外键
口诀:多对多,三张表,关系表两个外键

以上满足第一范式,但不满足第二范式,因为王老师、张三出现了多次,造成了数据浪费
第三设计范式
建立在第二设计范式,所有的非主键都直接依赖于主键,不能产生传递依赖
口诀:一对多,两张表,多的表加外键
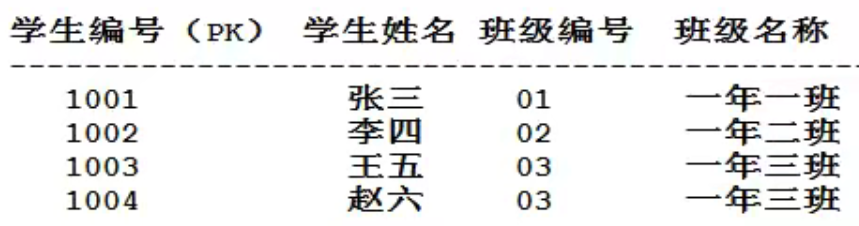
以上满足第二范式,但不满足第三范式,因为班级姓名依赖于班级编号
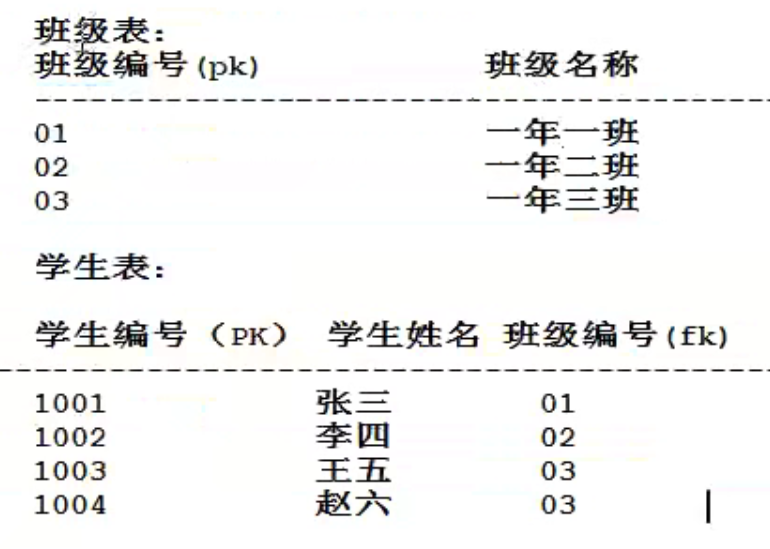
也是要多张表,避免产生依赖
一对一
如果一个表中的字段过多,可以考虑将其拆分开,拆分到多张表
例如
表user
id(pk) 姓名 年龄 性别 邮箱 昵称 密码
---------------------------------
可以拆分为两张表
表1 user
id(pk) userInfoID(fk+unique) 密码
---------------------------------
表2 userInfo
userInfoID(pk) 姓名 年龄 性别 邮箱 昵称
------------------------------------

Q.E.D.

